Make your AI admit when it’s guessing.
It uses the same calm, finished voice whether it knows the answer or it’s filling the gap. There’s no tell: the guess reads exactly like the fact.
Get it free →A real before-and-after is below ↓
The problem isn’t that your AI is wrong sometimes.
It’s that it uses the same voice for both. The certain tone. The tidy sentence. The answer that sounds exactly like what you were hoping to find. There is no tell. A figure quoted to two decimal places looks the same as one you could verify. A citation that does not exist reads identically to one that does. And the model has no reason to flag the difference, because it cannot see it either.
So you verify everything twice. Not because you’re cautious, but because the tone gives you no choice.
A real before and after.
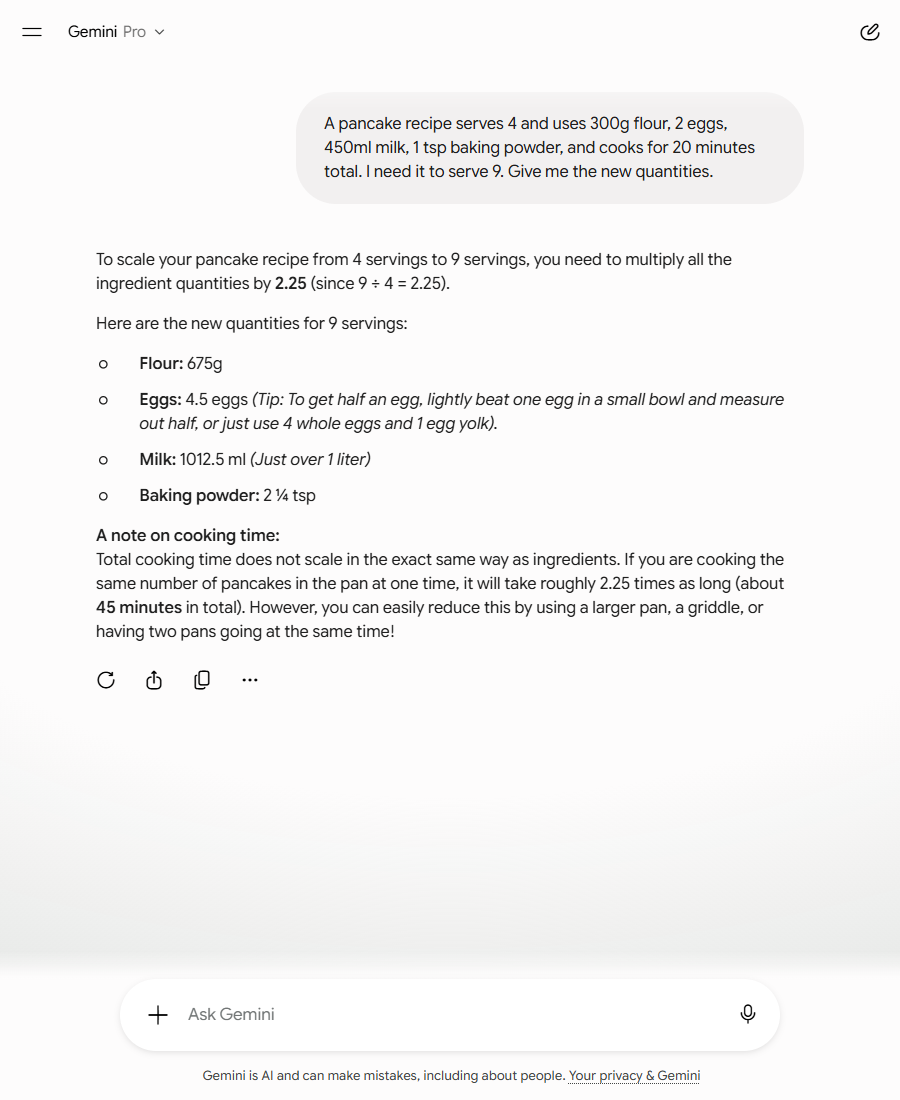
Pancakes. I asked four assistants to scale the recipe from four servings to nine. Two got the maths wrong, treating the 20-minute cook time like an ingredient to multiply. Here is Perplexity, the worst of them, on the exact same question: plain, then running the filter. Its own words, both times.
“Total cook time: 45 minutes”
Stated flat, with the same certainty it used for the flour: a straight 20 × 2.25. The batter doesn’t cook slower because there’s more of it. Confident, clean, wrong.
“plan on more than 20 minutes total if you cook in larger batches… check doneness rather than relying on a straight multiplication”
And in its working it named its own original error out loud: “rather than simply stretching 20 minutes to 45 minutes.” Same model. The prompt that fixed it was four lines long.
Where it earns its keep: free models, multi-step questions, and anywhere the answer is checkable and being wrong has a cost. The strong paid models handle the easy ones on their own; this is for the ones they get confidently wrong. The full four-model test, every verbatim answer, is here: I asked 4 AIs to scale a recipe →
→ Get the four-line filterWhat it actually is.
One short instruction set. You paste it into a Claude or ChatGPT Project once, or at the top of a chat, and your assistant follows it from then on. Nothing changes about the model. What changes is how it answers.
Scope
It names where the answer is good as of, and stops before it guesses past that.
Filter
It labels every claim: known, inferred, or a guess. Nothing stated as fact unlabelled.
Risk
It names what would prove it wrong. One thing. Named.
Verdict
A stated confidence level and a usable next step. Replaces the hedge-everything essay.
Tell me where to send it.
The ready-to-paste file, in your inbox in a minute. You’ll also get Confidently Wrong, the fortnightly note where I run five AIs through one real question and show which one’s bluffing.
No spam. Unsubscribe link in every email.
The paste-ready file comes by email, plus the next one when the method moves on. The method itself is open in full, on the Prompt Stack and on GitHub.