Ask AI to scale a recipe and it multiplies everything — including the cooking time, which doesn't work that way. The fix is four lines added to your prompt asking it to flag what doesn't scale cleanly. Two of four tools gave the wrong cooking time on the plain prompt; the structured one fixed the worst answer and improved the rest.
// On this page
Does ChatGPT get maths wrong? I wanted a concrete answer, so I typed the same pancake recipe into ChatGPT, Claude, Gemini and Perplexity and asked each one to scale it from four servings up to nine. A normal thing to ask. The recipe was simple: 300g flour, two eggs, 450ml milk, a teaspoon of baking powder, twenty minutes total to cook.
Three of the numbers are easy. You multiply the flour, the milk and the baking powder by the same amount and you’re done. The fourth one is a trap, and two of the four tools walked straight into it. Perplexity and Gemini both told me that nine servings would take 45 minutes to cook.
It won’t. The batter doesn’t get slower to cook because there’s more of it. That confident, wrong “45 minutes” is the whole reason this post exists — not because AI got something wrong, but because of how sure it sounded while doing it.
The test
The task was the same for every tool: take a pancake recipe that serves four — 300g flour, 2 eggs, 450ml milk, 1 tsp baking powder, 20 minutes total cooking time — and give me the quantities for nine.
I ran it through ChatGPT, Claude, Gemini and Perplexity on 19 June 2026, all on the same day, with each tool’s memory turned off so nothing was carried over from a previous chat. Then I ran it twice: once with a plain prompt, the kind most people would just type, and once with a structured prompt that asked the tool to do a bit more work. The second prompt is the interesting bit, and it comes later.
One thing to be straight about up front: the tools weren’t on an even footing. Claude was running on a paid plan (Opus 4.8); ChatGPT was on the free tier. That gap matters and I’ll come back to it. For now, the cooking time is the line to watch.
The plain prompt — what each tool said
Here’s exactly what I asked, the way anyone would:
A pancake recipe serves 4 and uses 300g flour, 2 eggs, 450ml milk, 1 tsp baking powder, and cooks for 20 minutes total. I need it to serve 9. Give me the new quantities.
Every tool got the flour, milk and baking powder right. They all multiplied by 2.25 and came back with 675g flour, just over a litre of milk, and 2¼ teaspoons of baking powder. No complaints there.
The cooking time is where they split apart.
Perplexity was the worst of the four. It listed the ingredients and then, with the same flat certainty it used for the flour:
Total cook time: 45 minutes
No “roughly”. No “but”. No mention that this might not be how cooking works. Just a number, presented as a fact, sitting in the list next to the ones that were correct.
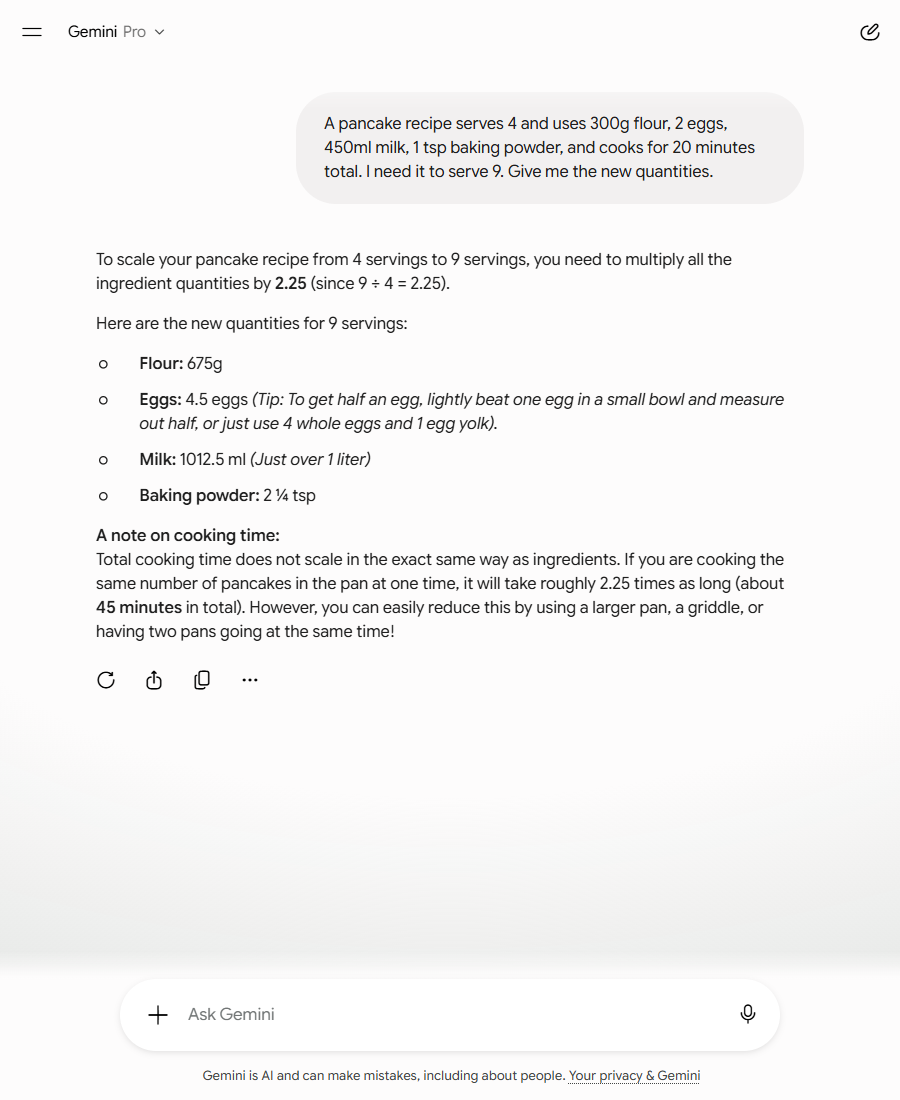
Gemini made the same mistake, dressed a little more carefully. It started by saying the right thing — “Total cooking time does not scale in the exact same way as ingredients” — and then undid it in the next breath:
it will take roughly 2.25 times as long (about 45 minutes in total). However, you can easily reduce this by using a larger pan, a griddle, or having two pans going at the same time!
So the headline number is still 45 minutes. The “fix” it offered — a bigger pan — speeds up a baseline that was wrong to begin with. You can see it on screen:
ChatGPT did better. It said the cooking time “stays about 20 minutes (you may need slightly longer if cooking in batches, but the batter itself doesn’t change cooking time).” Mostly right, but vague — it never quite explained why, so a reader is left to take it on trust.
Claude was the only one that caught the trap cleanly, and it did it without being asked:
One thing that does not scale: the cooking time. Pancakes cook in batches in a single pan, so each pancake still needs the same time on the heat — you’ll just have more batches to get through. The “20 minutes total” was for a panful at 4 servings; expect roughly double the total active time for 9 servings, but no individual pancake cooks any longer.
That’s the correct answer, unprompted, in plain English. It’s the kind of thing that goes on the catches log — the place I keep a record of AI getting something right when it didn’t have to.
// Want the next test in your inbox? Join the newsletter.
Why cooking time doesn’t scale
Here’s the bit I kept waiting for two of the tools to say, and they never did. Each pancake takes the same time to cook whether you’re making four or forty. What grows is how many goes you need at the pan. AI multiplied the time by 2.25 because it treated the twenty minutes like an ingredient — something you scale along with the flour. But it isn’t one. Per-pancake cook time is a fixed thing; the number of batches is what climbs.
AI multiplied the time by 2.25 because it treated the twenty minutes like an ingredient — something you scale along with the flour. But it isn't one.
That’s the class of error worth knowing about. Most numbers in a recipe scale cleanly. A few don’t, and they don’t announce themselves. A tool that multiplies everything by the same factor will get the cleanly-scaling numbers right and quietly fumble the one that doesn’t — which is exactly what happened.
The structured prompt — what changed
So I ran the whole thing again, same four tools, same day — but this time the prompt did one extra thing: it told each tool to slow down and check its own work. Same recipe, same question, four added instructions. This is the part worth copying:
A pancake recipe serves 4 and uses 300g flour, 2 eggs, 450ml milk, 1 tsp baking powder, and cooks for 20 minutes total. I need it to serve 9. Do four things: (1) state the scaling factor and show the arithmetic for EACH ingredient; (2) flag anything that does NOT scale linearly (e.g. egg counts must be whole, cooking time per batch, pan size); (3) give me one quantity I can sanity-check myself in ten seconds; (4) give the final scaled list with a confidence level (low/medium/high). Don’t just multiply blindly.
It’s the everyday version of the Prompt Stack — the same idea, stripped down to a kitchen question. You’re not asking for the answer; you’re asking the tool to show its working and own up to what it’s unsure about. And it changed the responses across the board.
Perplexity, which had flatly stated 45 minutes the first time, reversed itself. It told me to “plan on more than 20 minutes total if you cook in larger batches or a deeper pan; check doneness rather than relying on a straight multiplication” — and, in its working, named the original error directly: “rather than simply stretching 20 minutes to 45 minutes.” The prompt that fixed the worst answer was four lines long.
ChatGPT tightened up too. The vague hedge became a clean distinction: “Cooking time per pancake stays the same.” Exactly the thing it had left implied the first time.
Claude went deepest. It rated each part of the recipe by how confident it was — flour and baking powder high, the egg count medium because it’s a judgement call, and the cooking time “low as a single figure, high as ‘cook to doneness’.” Then the line I’d happily print on a tea towel: “Don’t set a 45-minute timer; cook to visual doneness.”
Where it falls short
Two honest caveats, because the method isn’t magic.
First, the tier gap. Claude was on a paid plan and ChatGPT was on the free one, and some of Claude’s stronger showing on the plain prompt is down to that, not to anything I did. Perplexity’s “Best” setting also routes to a model it doesn’t name, so I can’t tell you precisely what answered. These are real conditions of the test and I’d rather say so than pretend it was a perfectly level contest.
Second, and this is the one that matters: the structured prompt improved Gemini but didn’t fully fix it. Even after being told to flag what doesn’t scale cleanly, its answer still said “9 servings will take roughly 45 minutes in that same pan due to the number of batches.” It framed 45 minutes as a problem to solve with a bigger pan, rather than explaining that the per-pancake time never changes. The structured prompt narrowed the error. It didn’t erase it. So the claim here isn’t “this prompt guarantees a correct answer”. It’s “this prompt closes most of the gap, and tells you where the tool is unsure so you can catch the rest”.
Field Report
What worked: The structured prompt — asking each tool to flag what doesn’t scale cleanly — fixed Perplexity’s flat wrong answer entirely and improved every other response. Claude caught the cooking-time error on the plain prompt, without any prompting at all.
What didn’t: Gemini’s structured answer still stated “45 minutes” as the baseline to work around, rather than explaining that per-pancake time is unchanged. The method narrowed the error; it didn’t kill it.
Bottom line: Useful, with eyes open. For any AI task that mixes numbers which scale cleanly with ones that don’t (recipes, materials for a job, anything with a physical limit), ask it to flag what won’t multiply nicely before you act on the figures. The four-line structured prompt above is the thing worth keeping. What would change the verdict: a run where the structured prompt makes an answer worse, not better. I haven’t seen one yet.
The wrong cooking time is a low-stakes example of a habit worth watching. AI multiplies everything with the same confidence, so the number to be wary of is the one that doesn’t grow the way the others do — the constant hiding in a list of variables. The Playground runs this same plain-versus-structured comparison on a handful of everyday questions, if you’d rather see the before-and-after for yourself. But the lesson is simpler than the demo: the structured prompt is what gets the tool to name that one number out loud, before you’ve set the timer and watched the last pancake go cold waiting for it.

Ben tests ways of getting reliable answers from AI on his own investing — documenting what each model got wrong, what each one caught, and the prompts that survived the cuts. About Ben →
The site runs AI on real investing decisions. Start with the Prompt Stack for the four-stage framework, or the Field Guide PDF for the condensed version — free, no email.