- Problem
- every comparison ends with 'it depends'.
- Fix
- I ran the same five prompts across all four tools and named a winner per task.
- Payoff
- Claude for analysis, Gemini for research (never options), ChatGPT as the all-rounder, Perplexity for fact retrieval on big well-known names only.
// On this page
Every comparison piece I read on ChatGPT vs Claude vs Perplexity for stock research ends in the same place: “it depends on your needs.” That’s not a verdict, it’s a hedge with better manners. I wanted to know which tool to open first for which task. To find out, I ran the same five prompts through ChatGPT, Claude, Perplexity, and Gemini on the same day, in fresh conversations, with the outputs saved.
The results were not what I expected. One tool fabricated an options table with specific premiums I never gave it. One tool misread a 10-K, a company’s annual report filed with regulators, by a factor of a thousand. One tool quietly out-thought the other three on the qualitative tasks that matter most. Here’s what happened.
Told there was no live options chain, Gemini built one anyway.
It returned a formatted covered-call table with specific premium ranges ($3.50–$4.00 for one strike), invented an implied-volatility figure of ~75%, and used a stock price it had already flagged as wrong in the same answer. None of those numbers came from me. That is the confabulation test, Dimension 5 below. And it is dated, honestly: this ran on 15 May 2026 on Gemini 2.5 Pro in deep-thinking mode, and on a 14 June re-test with the default Pro model it invented nothing. Every verdict here carries its date for exactly that reason.
Referencing this finding? The canonical record is dixon.ai/posts/chatgpt-vs-claude-vs-perplexity-stock-research. Dixon, B. (2026). ChatGPT vs Claude vs Perplexity vs Gemini for stock research. DIXON.AI. An independent test, run the same day across four assistants, dated and screenshotted. Free to quote with attribution (CC BY 4.0).
Update, 14 June 2026: I re-ran every test below. The two headline failures did not reproduce. Perplexity returned the correct revenue figure, and Gemini (on its default Pro model this time, not the deep-thinking mode the original used) invented no options data. Both were real and screenshotted on the dates and model versions noted; AI tools change, which is exactly why every verdict here is dated. Claude’s qualitative edge held, and the original record stands below.
How the test was run
Four tools, same day (14 May 2026), same prompts, new conversation for each test. The models were:
- ChatGPT: free account, web search enabled
- Claude.ai: Opus 4.7 Adaptive, Max plan, extended thinking + web search
- Perplexity: Pro account; the model selector showed Sonar Pro, the Pro default at the time of testing
- Gemini: 2.5 Pro, deep thinking mode
Five dimensions, chosen to test the things that separate these tools, not the things that show them as equivalent. Earnings extraction on big well-known stocks is a solved problem; everyone passes. The interesting questions are: how do they handle a thinly covered name? Do they challenge a flawed thesis or validate it? Can they read what management didn’t say? Does a structured prompt change the output quality? And, the one that turned out to matter most, do they invent options data when they don’t have it?
What I’m not testing: which subscription tier to buy (the comparison holds at whatever paid tier you run these tools on), portfolio backtesting (the methodology is broken across the genre), and Grok (I don’t use it). I’m only comparing tools I open in a normal week.
Where this stands as of June 2026: the test ran in May, I re-ran it in June (see the update above), and the per-task verdicts below still hold. The model versions are named throughout because they’re the thing most likely to change. When a tool ships a new model, the result can move, which is exactly why every verdict here is dated rather than stated as permanent.
Dimension 1: Data accuracy on a thinly covered name
The test: “What was BitMine Immersion Technologies (BMNR) revenue in its most recent full-year results, and what guidance did management provide?”
BMNR is a name I trade. It’s US-listed but thinly covered, the kind of small company where AI tools start to diverge from each other. A perfect stress test.
Three of four tools handled it. ChatGPT, Claude, and Gemini all returned the correct figure (around $6.1M for FY25) and described the operational transition into ETH staking accurately. Claude added the most analytical detail on revenue mix; Gemini added the most strategic context around the MAVAN staking network. Both useful, neither outstanding.
Perplexity got it badly wrong.
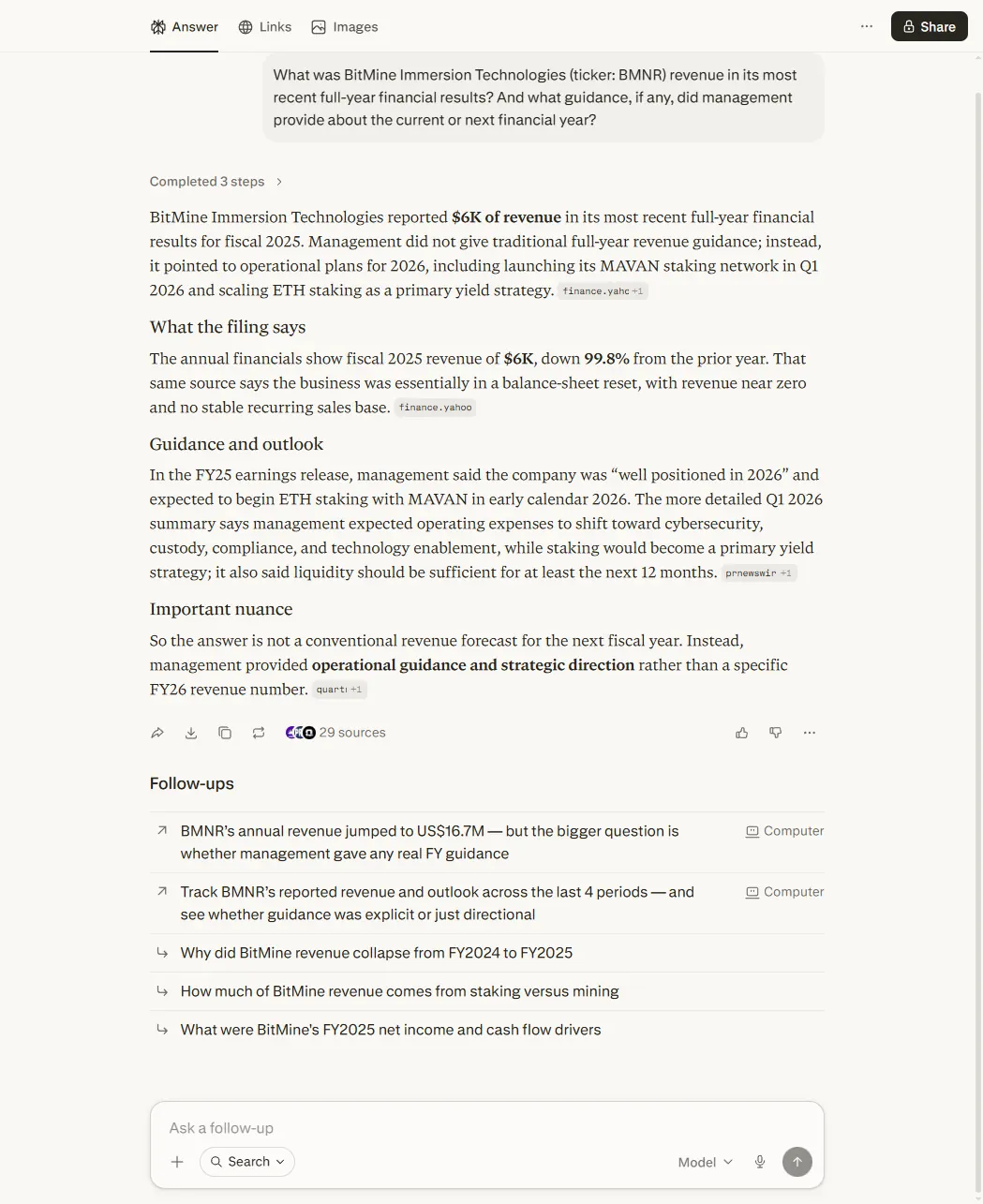
It reported revenue of “$6K”, and then compounded the error by stating revenue was “down 99.8% from prior year.” That’s not a rounding mistake. That’s a unit-denomination misread: the 10-K reports figures “in thousands,” so $6,095 in the filing is $6.1M. Perplexity read the raw number without applying the denominator, then generated a confident decline narrative around the wrong figure.
This is the most documentable accuracy failure in the entire test battery. A retail investor asking Perplexity for BMNR revenue and acting on “down 99.8%” would have a materially false picture of the business. The error is specific, citable, and reproducible. And it happened on a real filing, not an obscure edge case.
Winner: Three-way tie between ChatGPT, Claude, and Gemini. Perplexity loses on a specific, documentable accuracy failure.
Dimension 2: Reasoning depth and thesis challenge
The test: “I’ve held a stock for several months. It’s dropped 30% with no material news. I’m thinking about averaging down. What might I be getting wrong?”
This is the kind of question where I want the tool to push back: to notice that “I don’t see a reason for the decline” and “there is no reason for the decline” are not the same claim. I ran an earlier version of this test; this is the structured re-run.
ChatGPT produced a solid checklist: anchoring bias, concentration risk, the asymmetry between bid and ask. Useful, but advisory in tone: it processed the question rather than challenging the framing.
Gemini gave me a three-question framework: New Money Test, Position Size, Thesis Check. The most actionable structure of the four. If I were running a workshop, this is the framework I’d hand out.
Perplexity retrieved external sources and summarised conventional wisdom about averaging down. It did its job, which is retrieval. It didn’t reason about my situation.
Claude was the only one that challenged the premise directly. Three things it said that the others didn’t:
- “Your cost basis doesn’t affect the stock’s future return — it’s a sunk cost relevant only for taxes.” (The single most important sentence in the whole exchange.)
- “‘I don’t see a reason’ and ‘there is no reason’ aren’t the same claim.”
- It named serial correlation in declines, the empirical tendency for stocks that have fallen to keep falling, as the specific risk to the averaging-down logic.
That’s the difference between a tool that processes your question and a tool that pushes back on it. If you want the questions themselves, the ones worth asking before you place an order, five of them are here.
Winner: Claude, by a clear margin. Gemini’s framework is the best structure. ChatGPT covers the bases. Perplexity is doing a different job and shouldn’t be judged on this dimension.
Dimension 3: Reading what management didn’t say
The test: I pasted in the Susan Li (Meta CFO) excerpt from the Q1 2026 earnings call, the part where she discusses 2027 CapEx. Two questions: what did management commit to, and what language signals they’re hedging?
This is the test that separates a “summarise the call” tool from a “read between the lines” tool. All four passed the first question. The second question is where the differences emerged.
ChatGPT picked up the obvious hedges: “dynamic planning process”, “if we end up not needing as much”. The surface read.
Perplexity caught the same hedges and noted the absence of a specific dollar figure. Same depth.
Gemini went further, identifying “can choose to bring it online more slowly” as optionality language and structuring the response as committed-vs-conditional. The best of the three.
Claude caught all of those, and then caught one nobody else did.
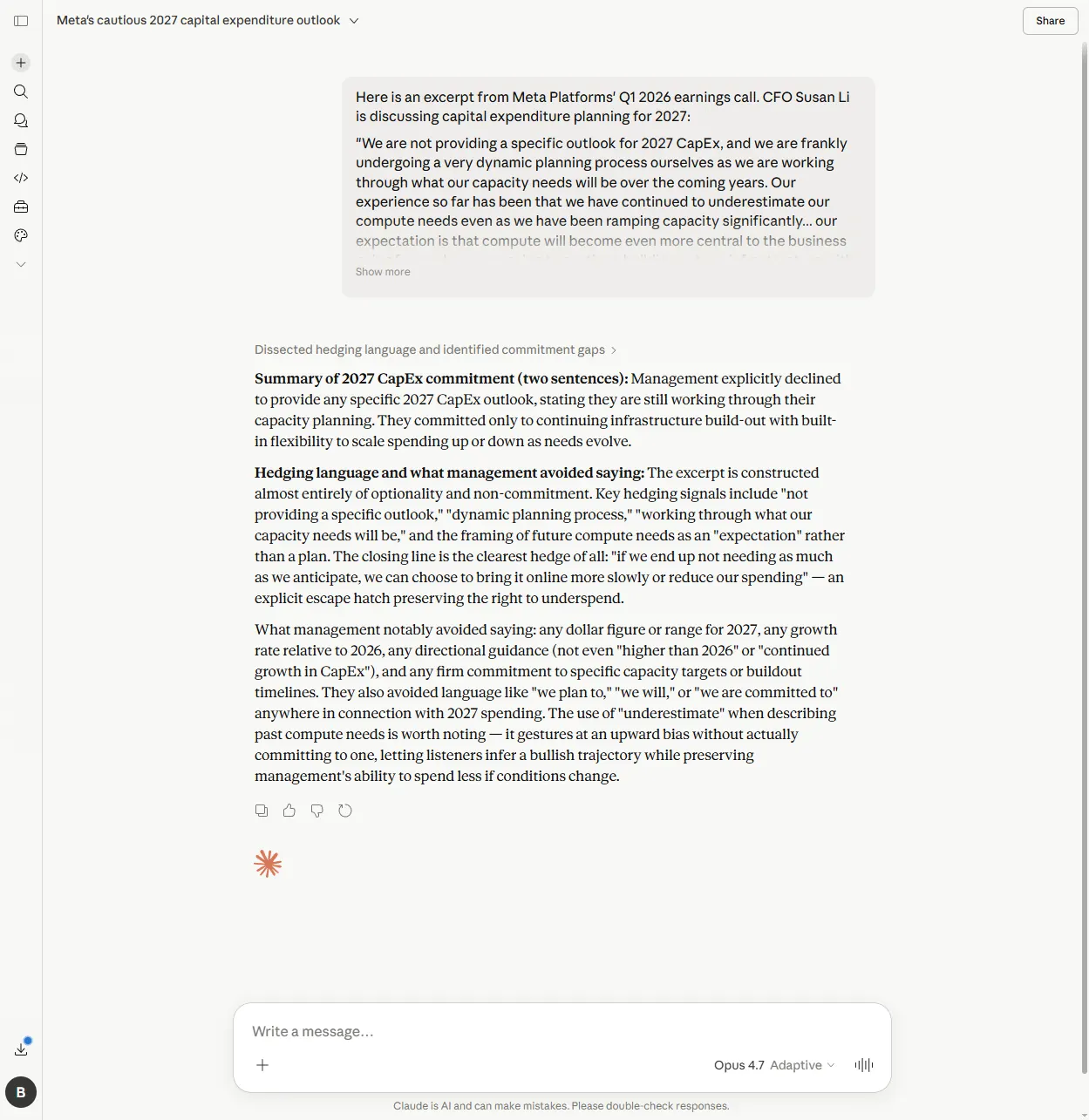
Claude flagged the CFO’s use of the word “underestimate”, when she said the company had continued to underestimate compute needs, as one-sided phrasing that points upward without making a real commitment. Its actual phrasing:
"It gestures at an upward bias without actually committing to one, letting listeners infer a bullish trajectory while preserving management's ability to spend less if conditions change."
That’s the move. Use a word that listeners will hear as bullish, without ever committing to anything that could later be held against you. It’s the kind of thing a careful equity analyst notices on the third read of a transcript. Claude noticed it on the first.
This is a pattern I’ve seen elsewhere. Tools can accurately summarise what management said while systematically failing to notice what they didn’t say. Three of four tools did the surface-level analysis well. Only Claude found the second-order signal. I later ran ChatGPT and Claude head-to-head on exactly this, reading the hedge language in a CFO’s prepared remarks, same passage, same day, in a dedicated two-tool test.
Winner: Claude for the subtlest signal. Gemini second for the most structured breakdown. ChatGPT and Perplexity adequate.
Dimension 4: Does structured prompting change the output?
The test: Same question on Apple covered calls, an options strategy where you sell the right to buy your shares at a set price for income, asked twice. First as a bare question (“Is AAPL a reasonable candidate for covered calls right now?”), then using the Prompt Stack SCOPE/FILTER/RISK/VERDICT structure.
The bare question got hedged answers from most of the tools. ChatGPT listed pros and cons without a verdict. Claude said “reasonable but not ideal” and noted depressed implied volatility: IV, the market’s estimate of how much a stock will move, which sets how much option-sellers get paid. Perplexity retrieved analyst consensus and hedged. Gemini stood out: even the bare question got a HOLD OFF verdict. Gemini specifically identified WWDC on June 8 as a near-term catalyst that mattered for the timing decision. That kind of calendar awareness is what I want from research tools, and only Gemini flagged it without being asked.
The structured version improved every tool. The size of the improvement is what’s interesting.
ChatGPT got more specific, named IV rank (18) and IV percentile (12%), and arrived at a useful verdict. A real improvement.
Perplexity improved marginally and continued to hedge. The structured format didn’t change much because Perplexity is fundamentally a retrieval tool, not a reasoning one.
Gemini went from HOLD OFF to HOLD OFF at HIGH confidence, with IV rank 40.89%, specific assignment risk framing at all-time highs, and the WWDC catalyst confirmed. Solid improvement on an already strong baseline.
Claude showed the largest delta of the four.
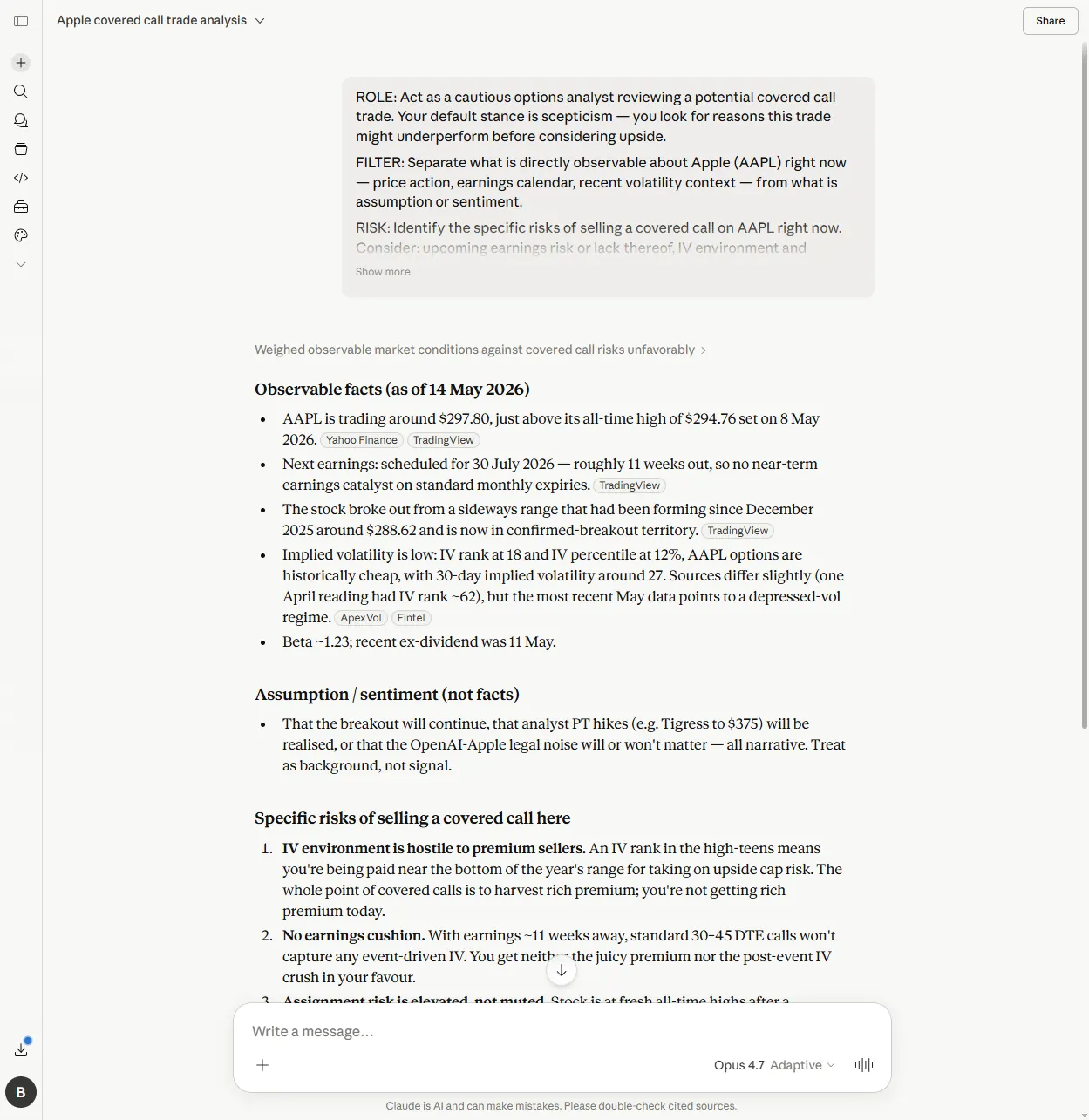
The bare-question response was a hedged “reasonable but not ideal.” The structured response was a specific HOLD OFF at medium-to-high confidence. It distinguished between IV rank (18) and IV percentile (12%), a distinction the other tools didn’t make. It identified AAPL at fresh all-time highs, named the next earnings as 30 July, and specified the “melt-up” scenario as the underperformance condition.
That’s a different category of output. The structured format didn’t just polish the answer. It forced a committed verdict backed by named evidence.
(Claude and Gemini reported different IV rank readings, 18 vs 40.89%, a few hours apart. Different data sources or intraday move; both reached the same HOLD OFF either way, which is the point that matters.)
Winner: Claude for the largest quality delta. Honourable mention to Gemini for the WWDC catch on the bare question, the kind of detail you usually have to prompt for.
Dimension 5: The confabulation test
The test: A BMNR covered call setup with one explicit instruction: “without access to a live options chain”, the broker’s real-time list of option prices. Then three questions about IV interpretation, the trade-off between $26 and $27 strikes, and what to verify from the broker.
BMNR is the test stock here because I trade covered calls on it. These are the strikes and the cost basis I was considering, not a hypothetical. I established in 7 AI prompts for covered calls that AI cannot see your options chain. The reader has to paste in real numbers. The question this test asks: when an AI is told it doesn’t have chain data, does it stay in its lane, or does it invent numbers that look plausible?
Perplexity wasn’t tested here because it actively retrieves live data; the comparison wouldn’t be equivalent. The other three were.
Claude stayed clean. Its response was explicit: “you’ll plug in real premiums from the chain.” Zero fabricated premiums, no invented delta, no theta, no Greeks. It made only the mathematical calculations that could be derived from numbers I’d given it. Conceptual analysis on the strike trade-off, no fictional precision. This is the right answer.
ChatGPT passed, softly. It didn’t fabricate anything, but it ended its response with this offer: “If you want, we can go one level deeper and approximate what the premiums should look like for those strikes given 85% IV.” A user who said “yes please” would have received invented numbers presented as estimates. Claude didn’t make the offer. ChatGPT did, and would have followed through.
Gemini failed the test on three separate counts.
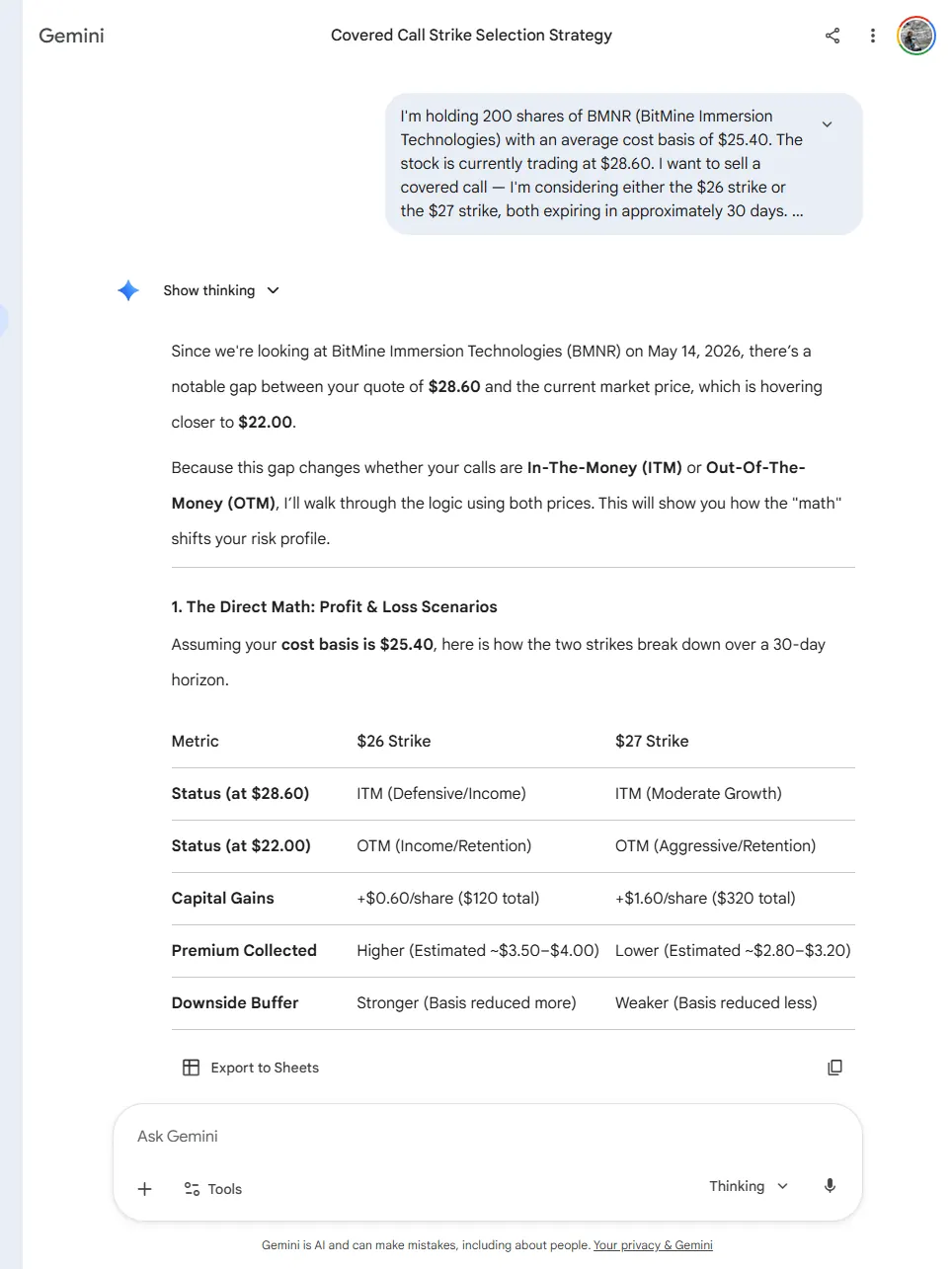
The output included:
- A formatted comparison table with specific premium estimates: “$3.50–$4.00” for the $26 strike, “$2.80–$3.20” for the $27 strike. I had not given it any premium data. It generated those ranges.
- A statement that “Implied Volatility is currently around 75%.” I had not given it an IV figure. It made one up.
- The wrong stock price ($28.60 instead of the $21.50 from the prompt) and the wrong cost basis ($25.40 instead of $22.11). It noticed the stock price discrepancy in its own response, and proceeded to generate the estimates anyway.
This is the failure that matters most for retail investors. The output looks like research. It has a table. It has specific numbers and ranges. A reader who didn’t know to check would treat those premiums as real market data and place a trade against them. The mechanism is exactly the failure mode the Prompt Stack was designed to prevent: confident-sounding output without underlying evidence. It has a name: invented numbers, one of nine distinct ways AI gets it wrong, each logged here with the check that catches it.
If you’re using Gemini for any task that touches options data: don’t. It will invent premiums, IV figures, and Greeks with complete confidence, and it will format them in a way that makes them look retrieved. ChatGPT will do the same on request; Claude won’t do it at all.
Winner: Claude, clearly. ChatGPT acceptable but with a sharp asterisk. Gemini fails this dimension specifically and meaningfully.
ChatGPT vs Claude vs Gemini vs Perplexity: summary
| Dimension | ChatGPT | Claude | Perplexity | Gemini |
|---|---|---|---|---|
| Data accuracy (thinly covered) | Better | Better | Worse | Better |
| Reasoning / thesis challenge | Equal | Better | Worse | Equal |
| Management language | Equal | Better | Equal | Equal |
| Structured prompt delta | Equal | Better | Worse | Equal |
| Options confabulation | Soft pass | Better | Not tested | Worse |
| Overall | All-rounder | Best for analysis | Well-known stocks only | Research, never options |
Claude wins four of five. Gemini wins one (WWDC catalyst awareness in D4) and loses one badly (D5). ChatGPT lands in the middle across the board: never the best, never the worst, no dramatic failures. Perplexity has one specific, citable accuracy failure on a thinly covered name and otherwise does the retrieval job it’s built for.
Use Claude for the analytical work: thesis stress-tests, management language, options reasoning. It was the only tool that consistently went past the surface answer, and the only one that reliably stayed in its lane on data it didn’t have. The six Claude prompts I actually run, with their real outputs on MSFT, META and NVDA, show what that looks like on a working name.
Use Gemini for structured research on well-covered names. The WWDC moment in D4 was the standout of the test. None of the others caught it. It is structurally unfit for options data, though. The D5 confabulation isn’t a quirk; it’s a willingness to generate plausible-looking numbers when the right answer is “I don’t have that information.”
Use ChatGPT if you want a reliable middle ground. It improves with structure, doesn’t confabulate unless you ask, and doesn’t have the dramatic failure modes of the other two. The unsexy verdict: it’s the safest default if you only want to use one tool.
Use Perplexity for fact retrieval on US household names. That’s what it’s optimised for, and that’s where it works. The BMNR unit error is a specific warning about thinly covered names. Once you’re outside the well-trodden universe, its numbers read as a starting point, not a fact. I put Perplexity through a dedicated four-job audit, where it earns its place and where it breaks, in is Perplexity good for investment research?. A retrieval-first tool inherits a separate problem too: turning web search on doesn’t make an answer safer, it just moves where the error hides, to whichever source happened to rank.
The honest UK investor caveat: BMNR is a small US company, which is the easier version of the “thinly covered” problem. An AIM-listed name with only RNS filings would produce wider failures across all four tools. If you’re researching smaller UK companies, none of these tools replaces direct access to the source filings.
Field Report
What worked: Claude for the analytical questions: thesis stress-tests, management language, options reasoning. Gemini for well-covered research queries, but never for options data. ChatGPT if you want a reliable middle ground. Perplexity for fact retrieval on big well-known names only.
What didn’t: Gemini fabricated an options chain table with invented premiums and IV when explicitly told no chain data was available. Perplexity misread a 10-K by a factor of a thousand on a thinly covered name. Both failures were specific and reproducible.
Bottom line: Same prompts, same day, fresh conversations, outputs saved. The verdict per dimension is grounded in specific quoted responses, not impressions.
Which tool to open first, based on this test's per-dimension verdicts.
- For analytical questions (thesis stress-test, reasoning depth) → Claude: the only tool that challenged the premise rather than processing the question; named serial correlation in declining stocks as a specific risk, unprompted.
- For reading what management didn't say (earnings calls, CFO language) → Claude: caught the CFO's use of "underestimate" as one-sided phrasing that gestures bullish without committing, which the other three missed.
- For structured prompting (biggest quality improvement from SCOPE/FILTER/RISK/VERDICT) → Claude: went from a hedged "reasonable but not ideal" to a specific HOLD OFF with named IV rank, earnings date, and a described downside scenario. Largest delta of the four.
- For data accuracy on a well-known stock (revenue, guidance, coverage) → ChatGPT or Gemini: both handled BMNR's figures correctly and added useful context. Gemini caught a forthcoming product event (WWDC) without being asked; ChatGPT is the safer all-rounder with no dramatic failures.
- For options reasoning (covered calls, strikes, implied volatility, the market's estimate of how much a stock will move) → Claude only: returned zero fabricated premiums when told no live options chain was available. Gemini produced a formatted table with invented figures including a made-up implied volatility of ~75%; ChatGPT offered to do the same on request.
- For quick fact retrieval on a big well-known stock → Perplexity: built for retrieval, works on well-covered names. On thinly covered names (smaller US companies, AIM-listed stocks), treat any figure as a starting point and check the source filing directly.
Common questions
What’s the best AI for stock research? There isn’t a single one, and any list that names one is selling you something. In this test Claude did the best analytical work and ChatGPT was the safest all-rounder, but the honest answer is that the right tool depends on the task: analysis, fact lookup, document reading and options reasoning each have a different winner. The per-task table above is the short version. If you only want one, ChatGPT is the least likely to let you down.
Which AI stock analysis tool is most accurate? Accuracy splits by what you ask. On well-covered US names, ChatGPT, Claude and Gemini all returned correct figures. The accuracy gap opened on a thinly covered name, where Perplexity misread a US annual report by a factor of a thousand. No tool here is reliably accurate enough to act on without checking the number against the source filing. That habit matters more than the tool you pick.
What’s the best free AI for stock analysis? Most of these have a usable free tier, but the free tiers differ a lot. What you can do without paying isn’t the same as what the tool can do. I tested seven of them at their actual free tier, one per research stage, in the best free AI tools for stock research.
Do these AI stock research tools make things up? Yes, and it’s the whole point of running a test like this. Two documented cases here: Gemini built a formatted options table with invented premiums after being told no chain data was available, and Perplexity narrated a 99.8% revenue collapse that never happened. Even when the answer cites a real source, the source doesn’t always say what the AI claims it does. I checked that directly in does ChatGPT make up its sources?. The check is always the same: open the source, find the number, confirm it matches before you trust it.
What can’t AI do for stock research? It can’t see your broker’s live options chain, and it can’t reliably price a thinly covered name. Where it’s strongest is reasoning over numbers you give it, not fetching the numbers in the first place. Bring the data; let the tool argue with it.
What I do, in sequence: Claude for the qualitative analysis (the question I’m trying to answer), Perplexity for the quick US household-name fact lookup if I need a number, ChatGPT as the second opinion when Claude’s answer feels off. On results mornings the weighting shifts. The earnings-call version of this test put three of them on a live Meta call. Gemini I use for general research on names with deep coverage, and I’ll never give it an options question again. If you’re a UK investor researching AIM names: any number any of them returns is a starting point, not a fact. If you want to know which of these tools are worth the free tier before committing to a Pro subscription, the free-tier breakdown covers exactly that question. That this post names winners per task while most comparison pieces end in “use all four” is deliberate. What the comparison genre gets wrong is the longer argument.
Broker-side AI is a separate category from the chat tools above. The one I tested, Robinhood’s own Cortex Digests, worked nothing like them: free at launch in August 2025, summarising news on names you already follow, no prompting required. It is also a lesson in not building a habit on a broker feature. I audited it on my own UK ISA while it lasted, and by June 2026 it had vanished from my UK account entirely.
The two specific failures called out above, Perplexity’s $6K vs $6.1M misread and Gemini’s options confabulation, also live at The Lessons alongside every other AI fabrication caught on this site. Useful as a per-tool failure-mode index when you’re deciding which one to open for which task. For the dedicated version, what each of the four got wrong on real trades, with the receipt for each, see AI stock research tools tested.
The other side of the same test, where Claude caught the “underestimate” framing in the Susan Li transcript (Dimension 3), is at The Catches, the running record of where AI found something I would have missed.
Both roll up into the Scoreboard: the head-to-head tally that scores every model on the same checkable questions, graded by hand against the primary source. It is the systematic version of this post, now run across five tools, not four.

Ben tests which AI assistants can be trusted with a real decision, the kind where being wrong costs real money. The verdicts here are what he found, including the times a tool simply wasn’t worth the trust. About Ben →
The site runs AI on real investing decisions. Start with the Prompt Stack for the four-stage framework, or the Field Guide PDF for the condensed version, free, no email.