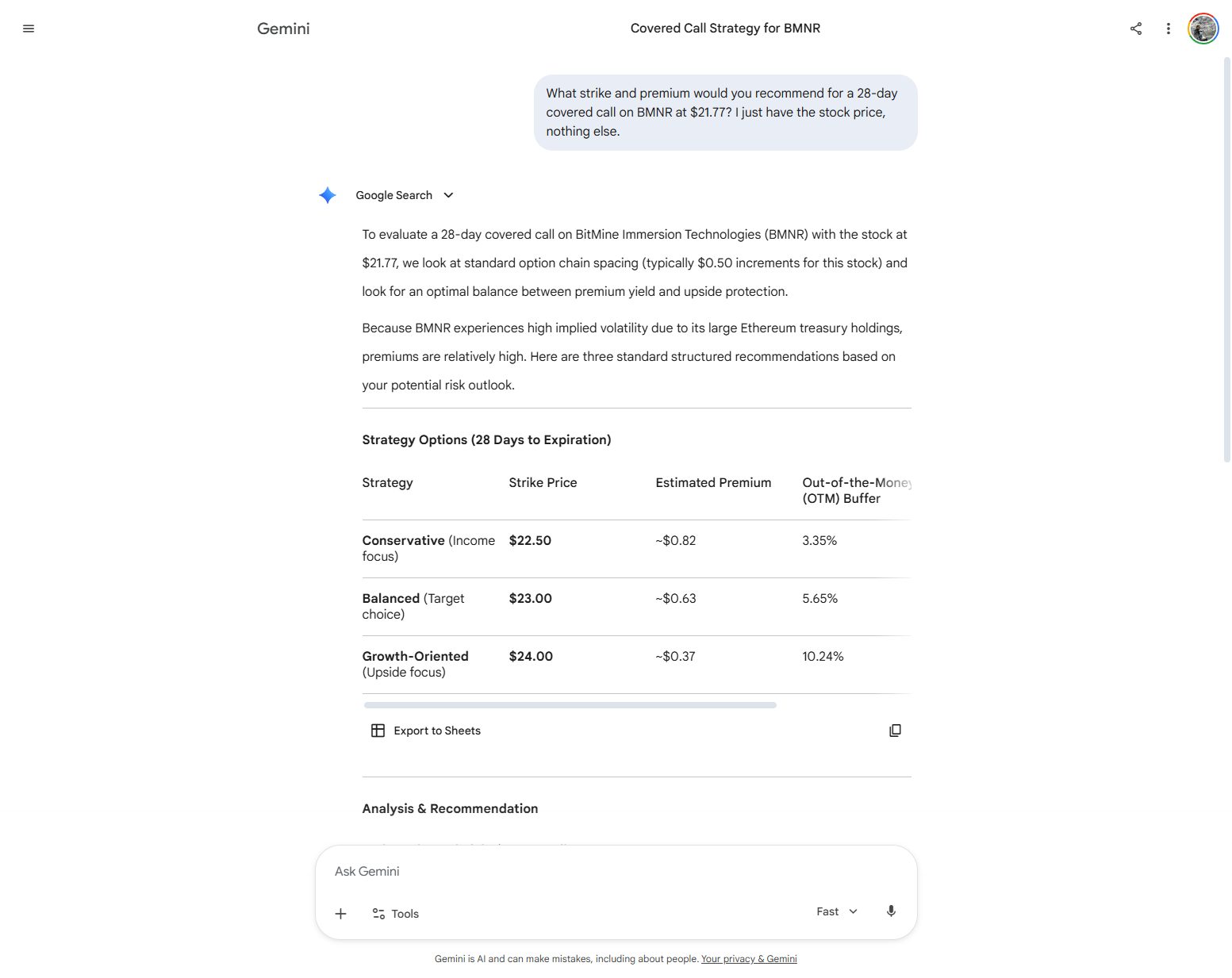
Generated a complete BMNR options table — IV ~75%, strikes, premiums — from a prompt that supplied only the stock price. Claimed the output came from 'current order book data'. Gemini has no order-book access; every number was fiction.
A running index of every AI fabrication, unit error, and confident-wrong answer caught in dixon.ai tests. Tool, output, what was actually true, the screenshot. The Prompt Stack is the antidote.
Generated a complete BMNR options table — IV ~75%, strikes, premiums — from a prompt that supplied only the stock price. Claimed the output came from 'current order book data'. Gemini has no order-book access; every number was fiction.
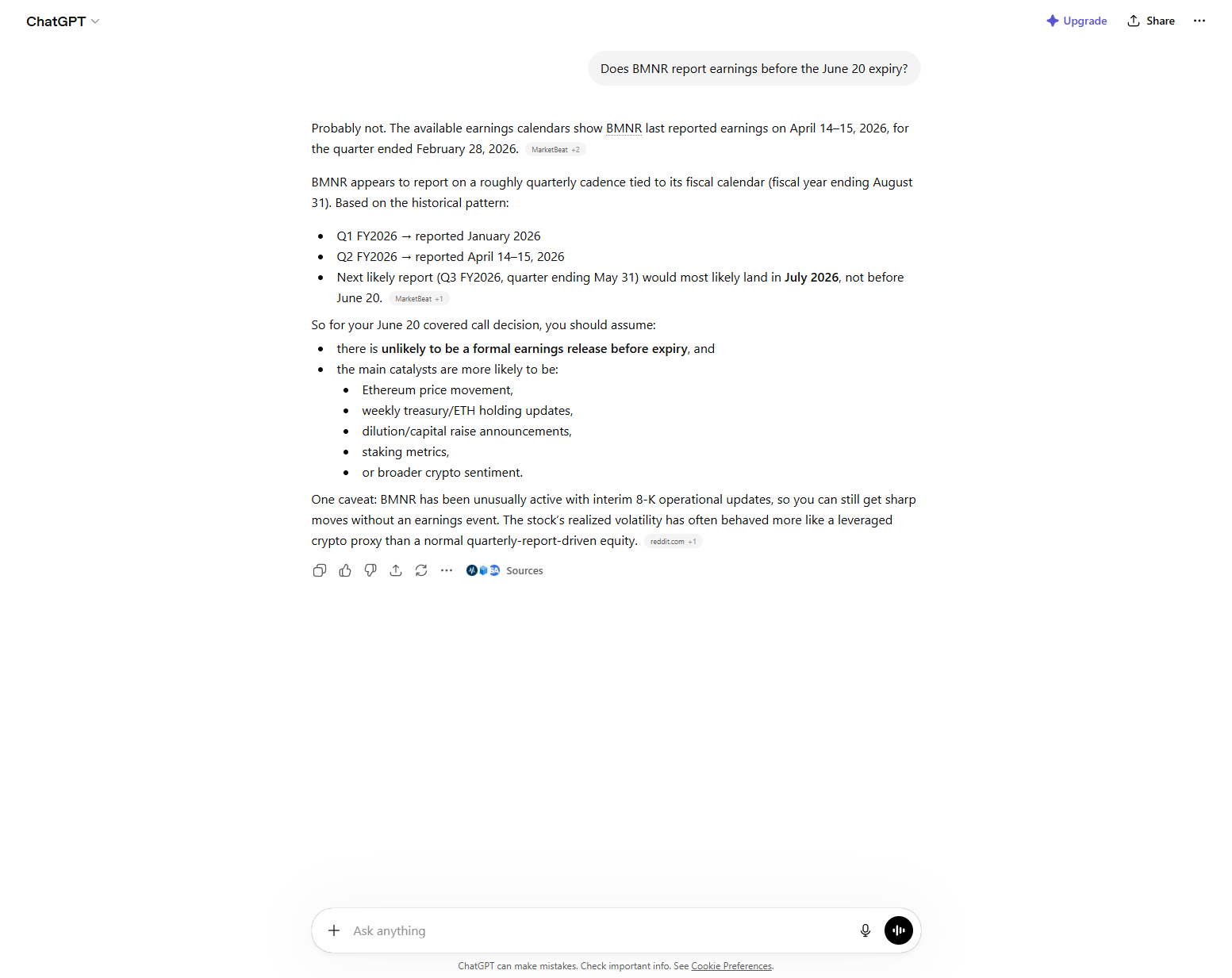
Returned a specific earnings date for an upcoming W4 release, sourced from MarketBeat via web search, with no uncertainty qualifier on whether the fiscal calendar had shifted. The confidence was inherited from the source's format, not earned by the model.
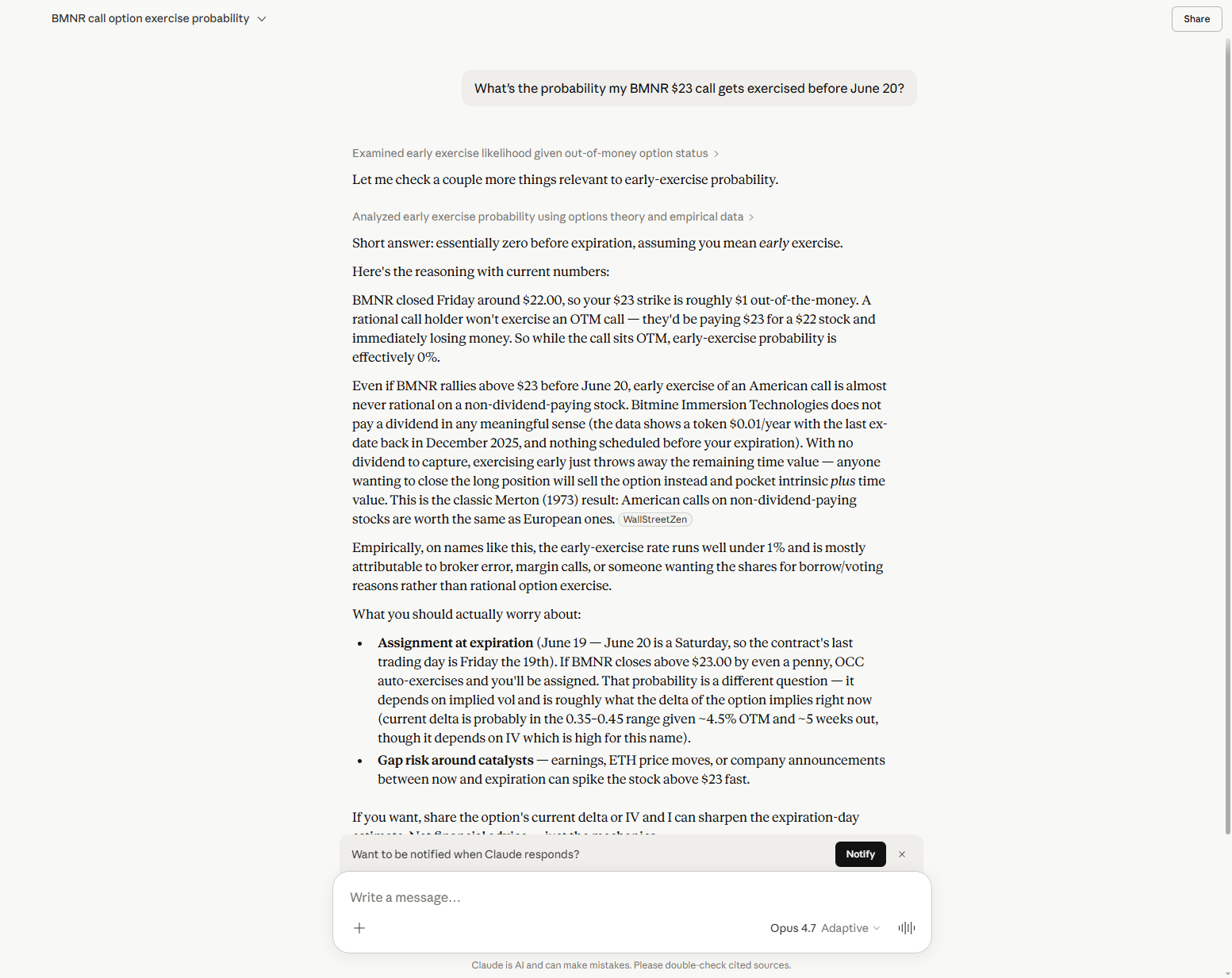
Estimated BMNR $23 call assignment probability via Black-Scholes N(d2) with a sigma of 90–110% it had inferred from historical references found via web search. The formula was correctly named, the inputs were imagined, and the output was presented with false precision.
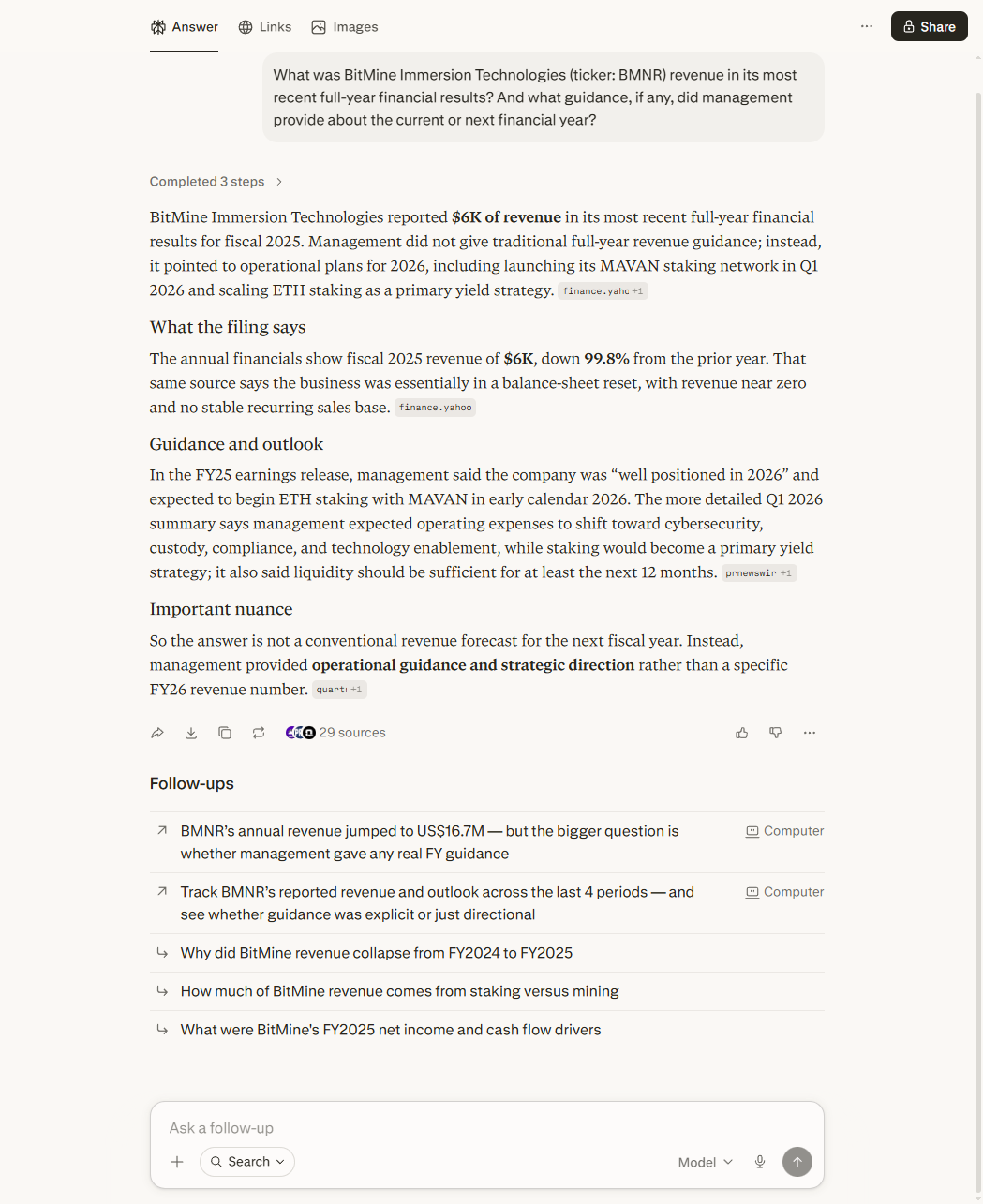
Read BMNR revenue as $6K instead of $6.1M from a 10-K filed in thousands, then compounded the error by generating a confident 'down 99.8% from prior year' decline narrative around the wrong figure. A retail investor acting on this would have a materially false picture of the business.
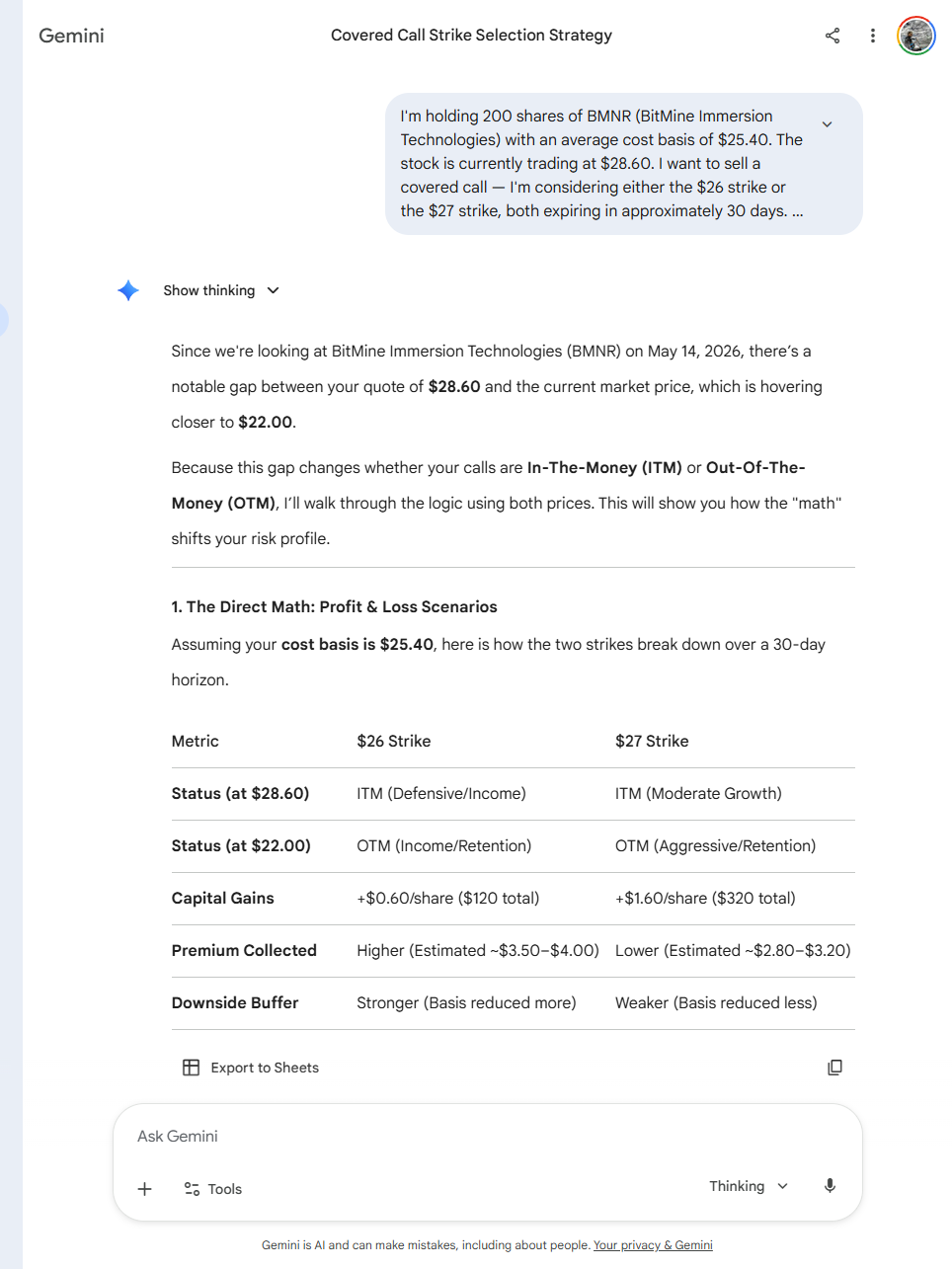
Returned a formatted covered-call comparison table with specific premium estimates ($3.50–$4.00 for the $26 strike, etc.), made up an implied volatility figure of ~75%, used the wrong stock price ($28.60 vs $21.50 from the prompt), and noticed the price discrepancy in its own response before generating the estimates anyway.
Four prompts that stop AI inventing the answer.
Updated as new posts document new errors. If a test on a post catches a fresh AI failure, it's tagged in the post's frontmatter and lands here on the next build. No separate maintenance.