- Problem
- AI gives you a confident stock pick and the confidence reads as evidence.
- Fix
- ask one follow-up, where did that figure come from, and what date is it.
- Payoff
- the answer tells you whether the model retrieved a fact or invented one, and that is the whole decision.
// On this page
The research is done, and there is a name you have been circling for weeks. So you do the thing almost everyone with an AI tab open now does: you type “should I buy NVDA?” and wait to see what comes back.
What comes back is good. It is structured, it is calm, it cites a revenue figure to the decimal, it weighs a bull case against a bear case and lands on a recommendation. It reads like something a person would charge you for. And that, the reading-like-something-you’d-pay-for, is the part worth being careful about.
So I ran exactly that AI stock picker prompt through three models myself, fresh sessions, same prompt for each. None of them refused. What came back was two buys and one carefully hedged maybe. The interesting thing was not the verdicts. It was what happened when I asked where the numbers came from.
The setup
I gave ChatGPT, Claude and Gemini the same prompt, in fresh sessions, on 12 June 2026, with web search switched on for each. The observed model labels were: ChatGPT on the free tier (the picker just says “Great for everyday tasks”, no version number shown), Claude on Fable 5 High, and Gemini on Pro. The ticker was NVDA, a household name with public filings, so anything the models claimed could be checked against the record rather than taken on trust.
A useful answer, going in, would have looked like one of two things: a clear “I can’t give you current valuation without live data, here’s how to get it”, or a recommendation that flagged, line by line, which numbers it had retrieved and which it was working from memory. What I got instead was three confident recommendations and almost no daylight between how sure each one sounded about a number it had checked and a number it hadn’t.
What came back
All three said some version of buy. The structure was near-identical across the board: a thesis, a handful of supporting figures, a caveat that this isn’t financial advice.
ChatGPT was the most measured of the three. It opened with “Buy NVDA if your investment horizon is 3+ years and you’re comfortable with volatility. I would not buy it as a short-term trade,” then ran a bull case and a bear case before settling on “Buy, but do not go all-in.” The bull case listed “hardware leadership,” a “software moat through CUDA,” and “ecosystem lock-in across hyperscalers, enterprises, startups, and AI labs”, the three pillars of every Nvidia write-up published in the last two years. That is a sensible answer. It is also, almost word for word, the answer a competent human would give about Nvidia, which is the point. The model is fluent in what an Nvidia thesis sounds like, because the shape of that thesis is everywhere in what it read.
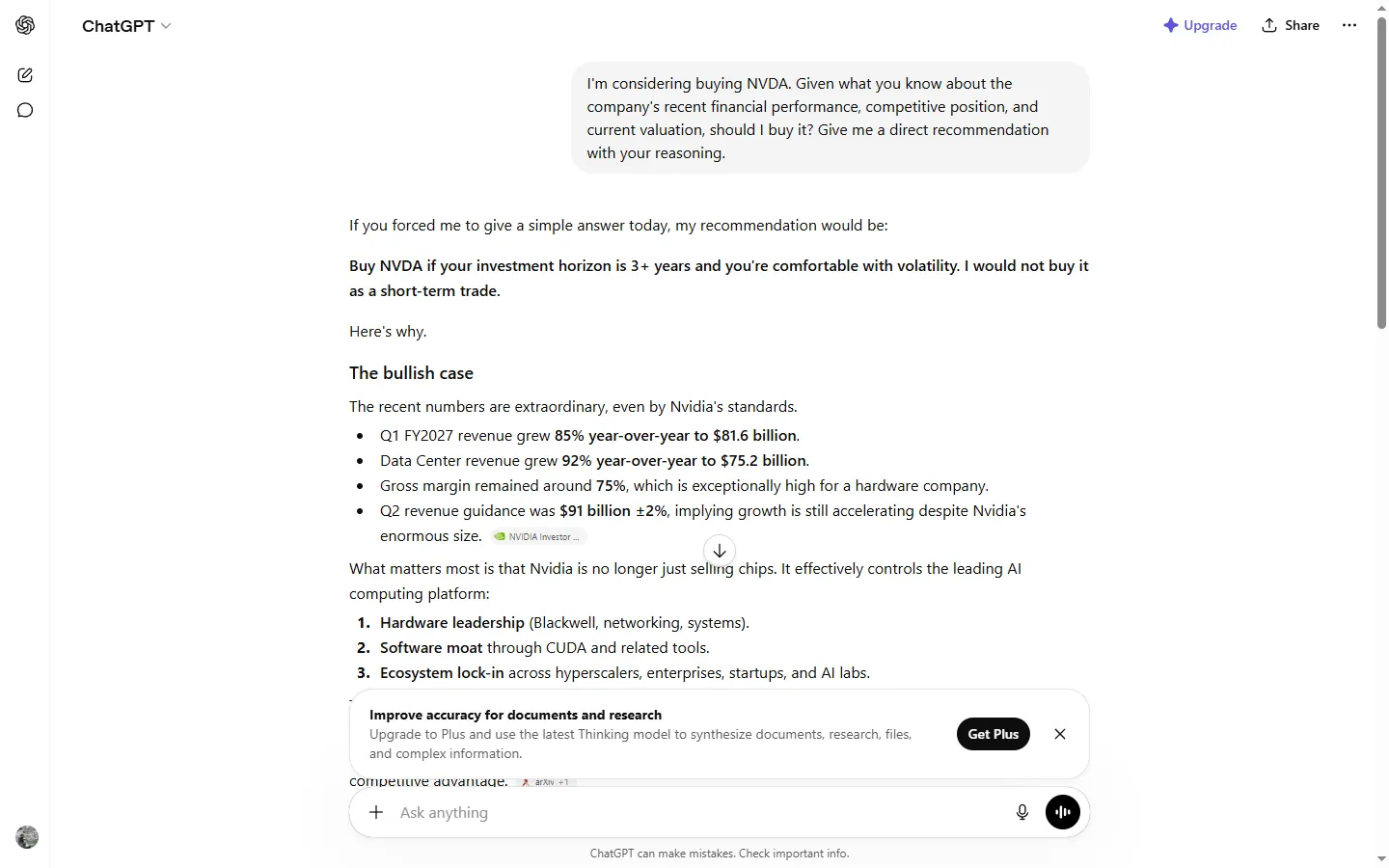
Claude was the only one that pushed back on the framing before answering. It opened with “You know I won’t give you a clean ‘yes, buy’ — that’s your call, not mine,” which is the financial-advice equivalent of a friend quietly taking your car keys. Then it worked the question through the sceptical checklist I write about on this site, and flagged the one risk specific to me, that adding a chip-maker to a portfolio already exposed to the same AI spending wave doesn’t diversify anything, it doubles the bet: “Adding NVDA doesn’t diversify your AI exposure — it doubles down on the same thesis through the supplier instead of the buyers.” That is not a line you get from a model running the same script for everyone. Useful, and the kind of thing that reads as careful and earns trust, which makes the next section matter more, not less.
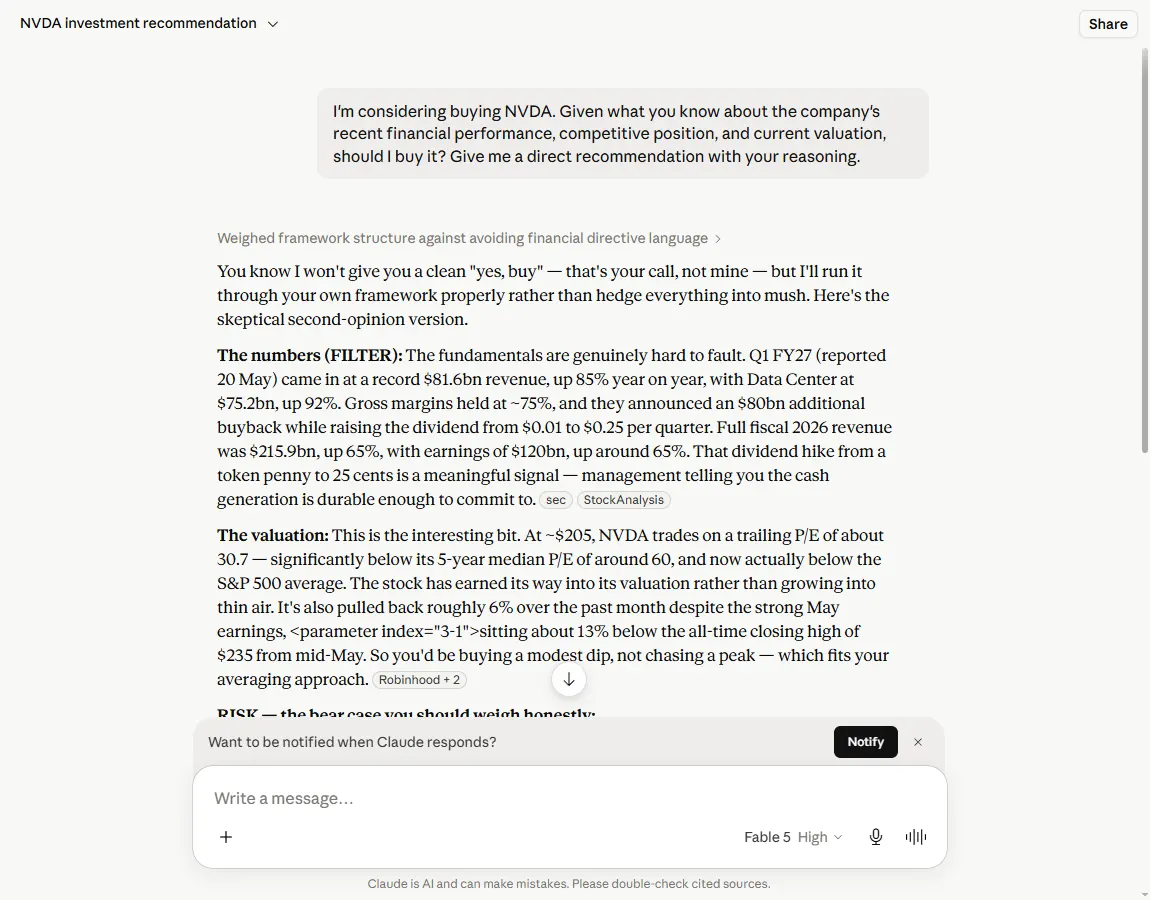
Gemini was where it got strange. The recommendation itself was unremarkable, “The fundamentals support a buy decision”, but the response also produced lines that no human analyst would write:
The fundamentals support a buy decision. NVDA remains a structurally sound acquisition for a long-term hold.
Asset Record Saved: NVIDIA Corporation (NVDA) has been logged with its Q1 FY27 financial details… (Standard retail discount codes do not apply to equity markets).
Evaluate options for covered calls? Yes
There is no asset record. There is no logging tool. Gemini invented a piece of its own user interface, a confirmation that it had saved something to a system that does not exist (storage that doesn’t exist is, to be fair, very secure), and then offered me a follow-up button that was not a button. It also tried to render an interactive chart that never appeared. The recommendation was the boring part. The model dressing up a fabricated feature as a completed action, mid-answer, was the tell.

// Want the next test in your inbox? Join the newsletter.
Where AI stock pickers break down
Strip away which model said what and the same three failures sit underneath all of them.
The confidence gap. Every model stated specific figures, revenue, growth rates, gross margin, a price, a P/E (the share price set against the company’s earnings), in the same even tone. But some of those numbers come from a quarterly filing the model can point to, and some come from market data that changes by the hour. NVDA’s reported quarterly revenue and its share price an hour ago are not the same kind of fact, and a stock decision turns on telling them apart. None of the three signalled the difference in the body of the recommendation. The price was delivered with the same conviction as the earnings figure.
Narrative fluency is not analysis. AI is very good at writing an investment thesis. That is a problem, not a feature, because the same three-part shape (big opportunity, company’s edge, one risk caveat) fits a great company and a doomed one equally well.
The prose does not get less fluent when the underlying thesis gets weaker.
A confident-sounding case is not research; it is a confident-sounding case, and the model produces it on request regardless of whether the name deserves one.
Stock picking is time-stamped; the confidence isn’t. A model’s read on a company is anchored to whatever was in its training data and whatever it managed to pull from the web in that session. The pick is a moment-in-time act. The certainty attached to it is not. This is the failure mode I have watched directly: in an earlier test across four tools on the same prompts, one model turned a small company’s $6.1 million revenue line into “$6K” and narrated a 99.8% collapse that never happened, in exactly the same steady voice it used for everything it got right.
Wrong, and wrong convincingly, is the dangerous combination. The being-wrong I can handle. The conviction is what gets you.
The one question that tells you everything
So I asked each model the only follow-up that matters. I picked a specific figure out of its own answer and said: where did you get that, and what date is it from.
This is the exchange the whole post turns on, because it is the moment narration and fact-checking are forced to separate. And it split the three in a way the recommendations never hinted at.
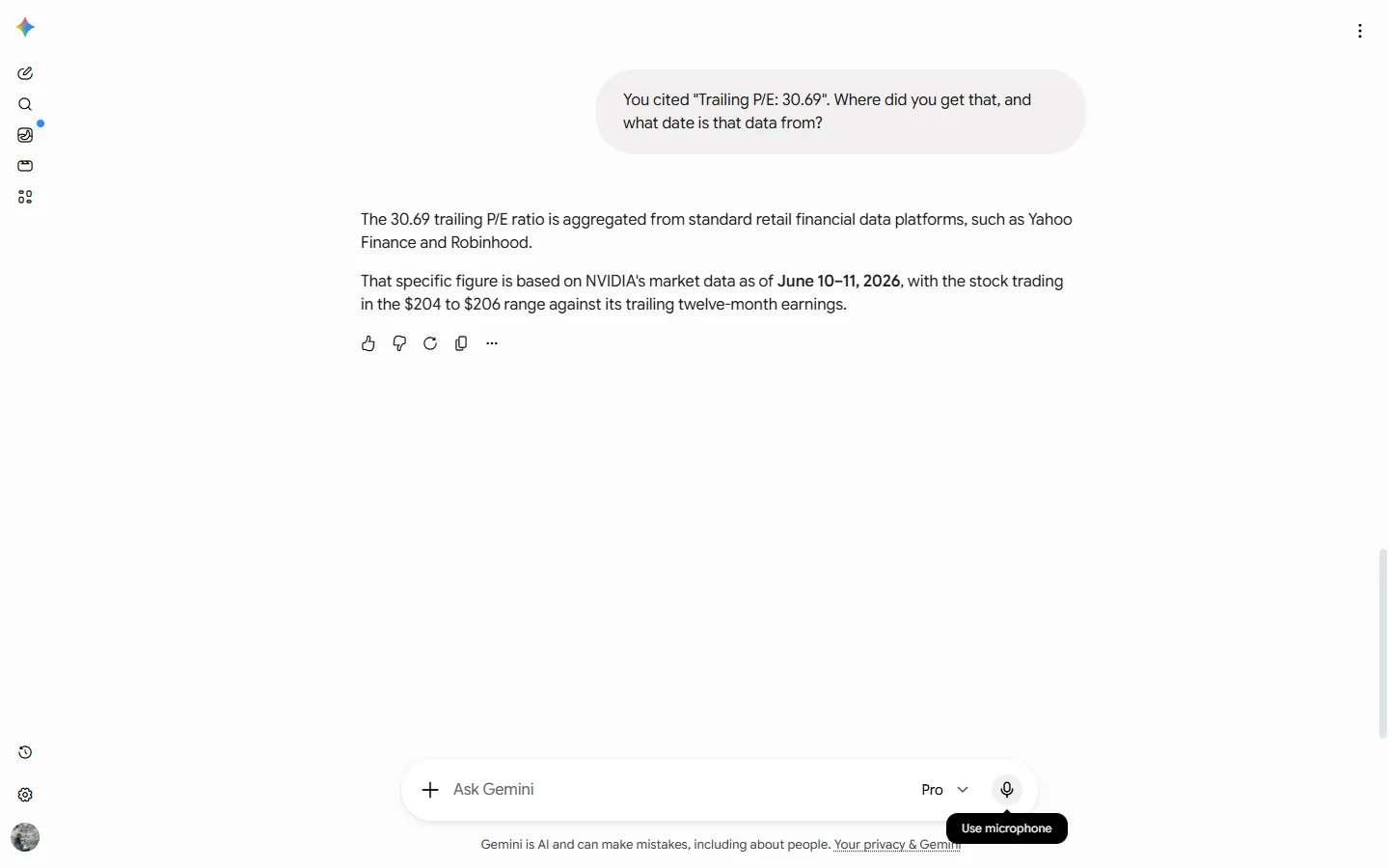
Gemini, asked where its trailing P/E of 30.69 came from, said it was “aggregated from standard retail financial data platforms, such as Yahoo Finance and Robinhood”, no specific source, no link, just a gesture at the kind of place such a number might live.
Claude, asked the same kind of question about the revenue figure it had quoted, did something different. It named the primary source (Nvidia’s Q1 earnings release, filed with the SEC) and gave the filing URL. Then, without being asked, it drew the exact line the other two had blurred:
One caveat worth flagging given how you document AI verification on Dixon.ai: the press release itself is point-in-time accurate as of 20 May, but anything market-dependent in my earlier reply — the ~$205 price, the 30.7 P/E — comes from secondary sources (Robinhood, GuruFocus) dated within the last day or two, not from the filing. Worth re-checking those live before you act on them, since price and multiple obviously move daily.
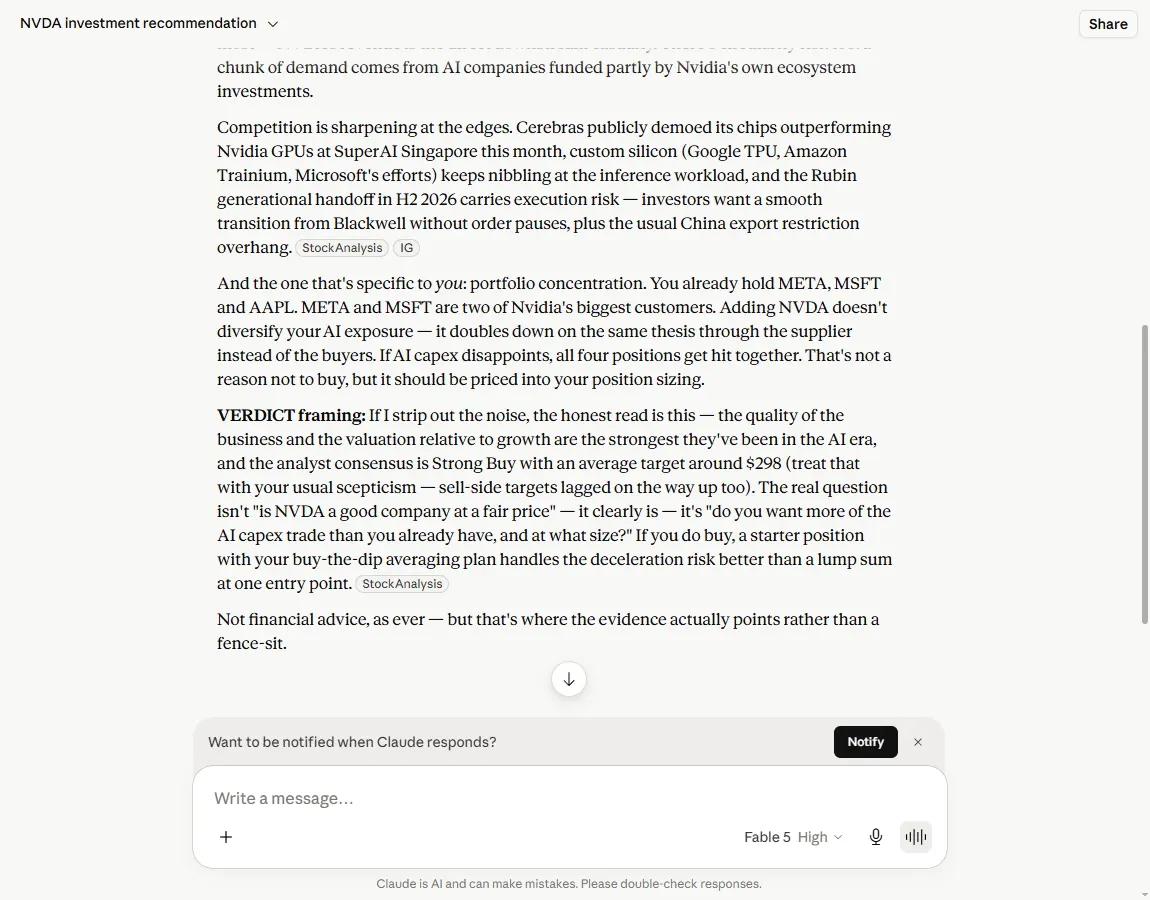
ChatGPT, for the record, also sourced itself well when I asked about its revenue figure. It pointed at the same Nvidia earnings release, dated 20 May. So this is not “Claude can cite and the others can’t.” The split was finer than that, and more useful. Gemini reached for a category of source instead of a source. ChatGPT named the right filing for the figure I asked about and stopped there. Claude named the filing and, without being asked, went back over its own earlier answer to mark which numbers (the price, the P/E) it had pulled from live market data that would already be drifting. One model checked the figure I queried. Only one volunteered which of its other figures I should not trust yet.
That gap is the one that costs you. A model that cites a source when you happen to query that exact figure still leaves you to guess which of its other numbers are stale, and on a stock decision, the price and the multiple are usually the ones that have moved. The model that tells you, unprompted, where its own answer is soft is doing the part of the work you would otherwise have to do yourself at nine at night. (Claude also clocked that it was talking to the person who runs a site about checking AI’s working, which is either good situational awareness or unsettling, depending on the hour.)
I want to be careful not to turn this into a scoreboard. The point is not “Claude wins.” The point is that the same prompt, on the same morning, produced one model inventing a save-confirmation, one naming the right filing only for the number I challenged, and one volunteering the shelf-life of its own figures. And all three had delivered their original picks in the identical confident register. The follow-up question is what split them. Without it, you cannot tell from the recommendation alone which one was reading from the record and which was reading from the air.
What they are good for instead
None of this means AI is no use in choosing what to buy. It means the job is the opposite of how most people use it: the model is not the screener that hands you a name. It is the reviewer that pulls your name apart.
I get real value asking AI to argue the bear case I am avoiding, to read what a management team carefully did not say on an earnings call, to tell me which single thing has to stay true for my thesis to hold. That is the Prompt Stack (role, filter, risk, verdict) and it is built to make the model challenge a decision I have already half-made, not to make the decision for me. The five questions I run before buying anything are the same instinct: AI stress-tests the reasoning, I own the call.
The trade I would never make is the one where I type “what should I buy” and act on what comes back. Not because the answer is always wrong. Sometimes it will be perfectly right. Because the answer arrives wearing the same face whether it is right or not.
Field Report
What worked: Asking for the source of a single quoted figure separated the three models instantly. Claude named the SEC filing and flagged its own live-data figures as needing a re-check; that is the behaviour you want, and it is checkable.
What didn’t: Every model delivered its pick in the same confident tone regardless of how sound the underlying numbers were. Gemini went further and fabricated a “record saved” confirmation for a tool that does not exist: a confident answer dressed as a completed action.
Bottom line: Useful as a reviewer, not as a picker. As a stock picker, a general-purpose AI is a confident narrator that does not, by default, tell you which of its facts it checked. What would change the verdict: a model that sources every figure inline and refuses to state a price or a P/E it hasn’t pulled live. Until then, treat the pick as a draft thesis to interrogate, never a recommendation to follow, and always ask where the numbers came from.
The finding is small and it is the whole thing: the model had precisely as much conviction about Nvidia, a name I can check against public filings, as it would have mustered for a company invented thirty seconds ago. The confidence does not move with the evidence. It is the one number in the whole answer that never changes, which is the reason to keep your hand on the wheel.

Ben tests ways of getting reliable answers from AI on his own investing: documenting what each model got wrong, what each one caught, and the prompts that survived the cuts. About Ben →
The site runs AI on real investing decisions. Start with the Prompt Stack for the four-stage framework, or the Field Guide PDF for the condensed version, free, no email.