This is the kind of thing the Bluff Filter catches. It’s free →
// On this page
The question I typed is an ordinary one, the kind people bring to an AI all the time: I’m choosing between two index funds for a long-term account, which is better? An index fund is a basket that tracks a whole market rather than picking individual companies, the default starting point for most people who just want to own shares and get on with their lives. It is also, it turns out, a good test of whether ChatGPT is accurate.
I wasn’t deciding anything that evening, though these aren’t abstract funds to me. I’ve held the US one for years; it was my first investment, before I ever picked an individual stock, and the global one is where I plan to move as I make the portfolio safer over time. That history is partly why I’d notice if an answer drifted. I picked the question because the facts behind it are externally checkable: every figure sits on a published factsheet I could hold the answer against. So I asked the same question, fresh, on four AIs in one evening: ChatGPT, Claude, Gemini and Perplexity. Then I did the boring part nobody does. I checked every number.
The short answer to “is ChatGPT accurate?” is: accurate enough to be dangerous. It got the cheap, fixed facts right and then handed me precise-sounding figures that were simply wrong, with exactly the same confidence either way. The only way to tell the two apart was to look them up myself.
The question, and why these numbers
I asked each AI to compare two well-known Vanguard funds (one tracking the 500 biggest US companies, one tracking around 3,700 companies across the whole world) on four things, then pick one for a buy-and-hold investor and say why. The four things:
- The ongoing charge (the OCF: the yearly fee the fund takes, shown as a percentage of what you’ve invested). This is the clean right-or-wrong test: it’s a single published number.
- The dividend yield (the income the fund pays out each year, as a percentage).
- The number of holdings (how many companies are in the basket).
- The five-year return (how much it grew over five years).
The fee is the honest test because there’s one correct answer printed on the factsheet. The yield and the return are fuzzier: they shift depending on the date and the data provider, and that fuzziness turned out to be a lesson of its own.
Here’s what ChatGPT gave me.
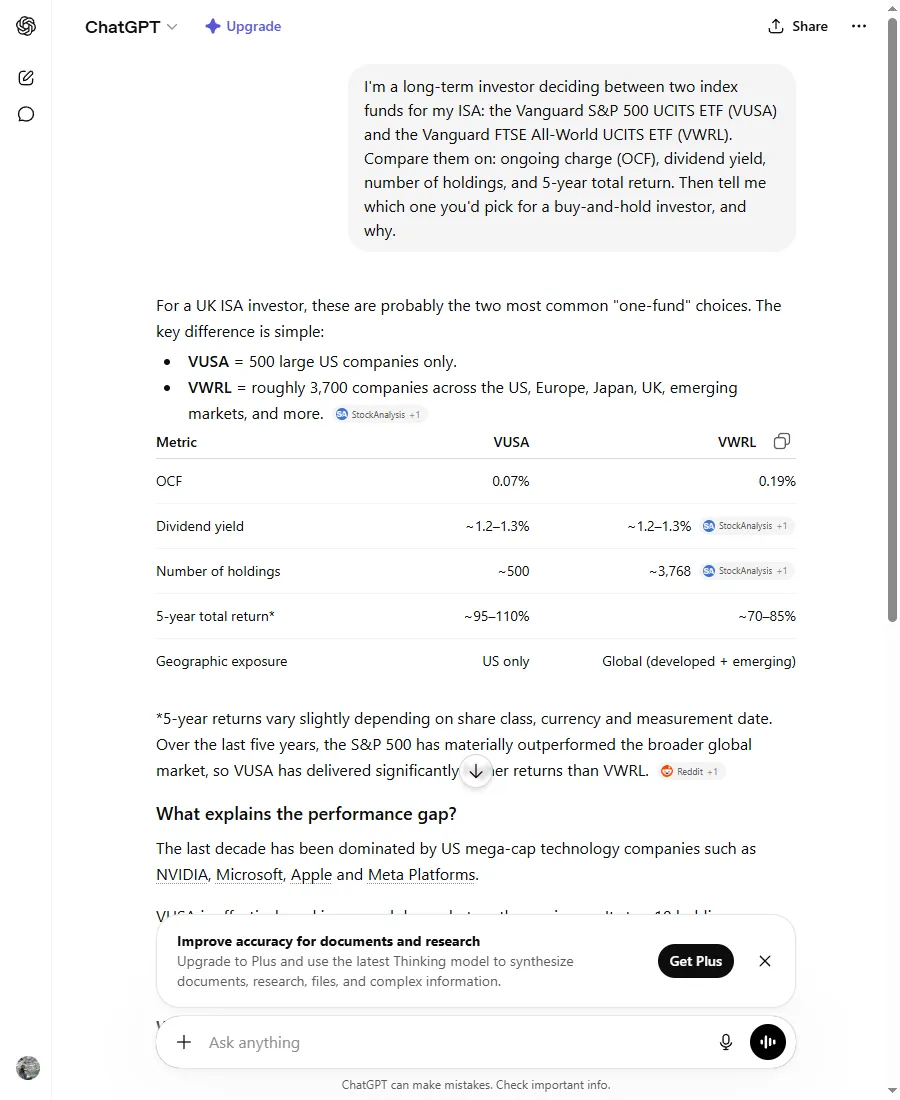
ChatGPT, 13 June 2026. The fee row is right. The yield row is the problem.
ChatGPT: right on the fixed facts, confidently wrong on the precise ones
ChatGPT got the fees right: 0.07% for the US fund, 0.19% for the global one. It got the rough number of companies right. It even searched the web and cited its sources, and its final pick (the globally diversified fund, on the reasoning that you don’t have to guess which country wins the next decade) was sensible. If I’d skimmed it, I’d have walked away impressed.
Then look at the dividend yield row: roughly 1.2–1.3% for both funds. That’s a tidy, plausible, identical-looking pair of numbers, and the “identical” is the tell, because these two funds don’t pay out the same. The global fund’s figure is roughly right (around 1.25%). The US fund’s isn’t: its real income is about 0.9%, not 1.2–1.3%. ChatGPT flagged no uncertainty on either figure. Both sat in the same table, in the same clean format, as the fee it got right. Nothing in the presentation told me which number came from a factsheet and which came from somewhere it couldn’t quite name.
The made-up number and the correct number wore the same face. The only way to tell them apart was to look them up myself.
That’s the whole problem in one table. The danger isn’t that ChatGPT is often wrong. It’s mostly right. The danger is that it’s wrong with the same steady confidence it uses when it’s right, so there’s no tell. A friend who only sounds certain when they know would be useful. A friend who sounds certain about everything is just someone you have to fact-check, which is most of the work you wanted to skip.
The bit that made me uncomfortable: I almost made the same mistake
Here’s where it stopped being a story about the machines.
Checking the fee, I nearly “corrected” the right answer. I was fairly sure the global fund charged 0.22%, the figure I’d carried in my head for ages. So when ChatGPT said 0.19%, my first instinct was that ChatGPT had it wrong. It didn’t. The fee was cut to 0.19% and my memory was stale. I was about to confidently overrule a correct machine with an out-of-date human.
And then Claude did exactly what I’d nearly done. Claude ran a web search before answering, I could watch it pulling current data, and still served the old 0.22%. The one tool that went and looked served the out-of-date number anyway.
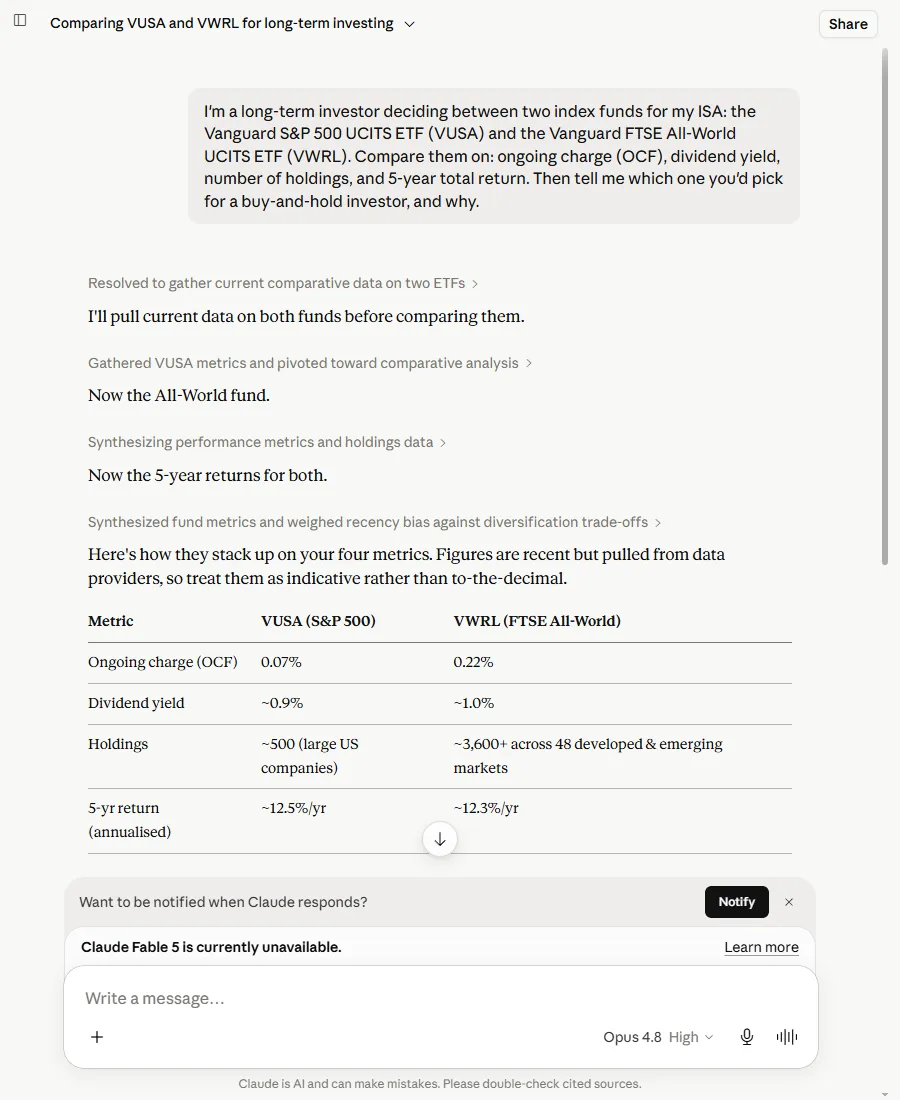
Claude, same question. The steps at the top show it searched for current data. The fee row underneath is the old number anyway.
That’s the beat worth keeping. Verifying isn’t something you do because the AI is dim and you’re sharp. I’m not reliably sharper than the machine here. I had the same wrong number in my head, and the tool with live web access landed on it too. The check earns its place precisely when I’m most certain I won’t need it.
Gemini quietly changed the answer just for me
Gemini got the fee right: 0.19%, current. But it did something none of the others did, and I didn’t ask it to.
Halfway through a neutral fund comparison, it reached into my account history and tailored the answer to me personally: referencing the kind of higher-risk investing it knew I do from earlier conversations, and recommending the safe global fund as a “bedrock” to anchor those riskier holdings. None of that context was in my question. It was the conversational equivalent of asking a stranger the time and having them mention, helpfully, that you really ought to get more sleep. At the bottom it displayed a small banner: “Gemini is still catching up on your past chats.”
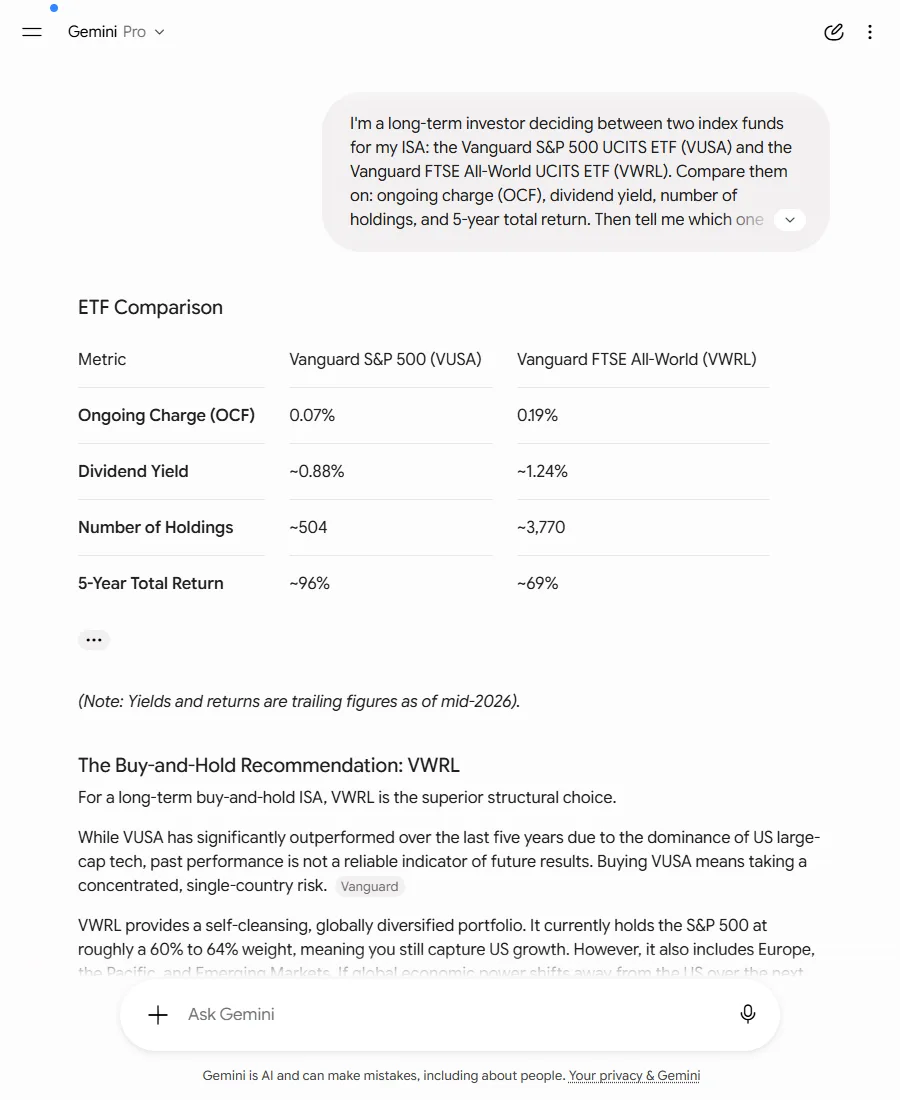
Gemini, same question, same evening. The table is fine. The personalisation underneath it isn’t in the question.
The advice it gave me wasn’t bad. But it wasn’t the answer to the question I asked. It was the answer to a question about my situation that it had assembled from memory, without telling me up front. Which means the same “standard” question gives a different reply to every logged-in user. There’s no single Gemini answer to hold against a factsheet, because there’s no single Gemini answer. Yours and mine would differ, and neither of us would be told why.
Perplexity put two incompatible numbers in the same column
I asked Perplexity the same question, and it cited 29 sources, which sounds like the careful one of the bunch. Then it built a comparison table with two five-year returns sitting side by side: 86.21% for the US fund, 11.83% for the global one.
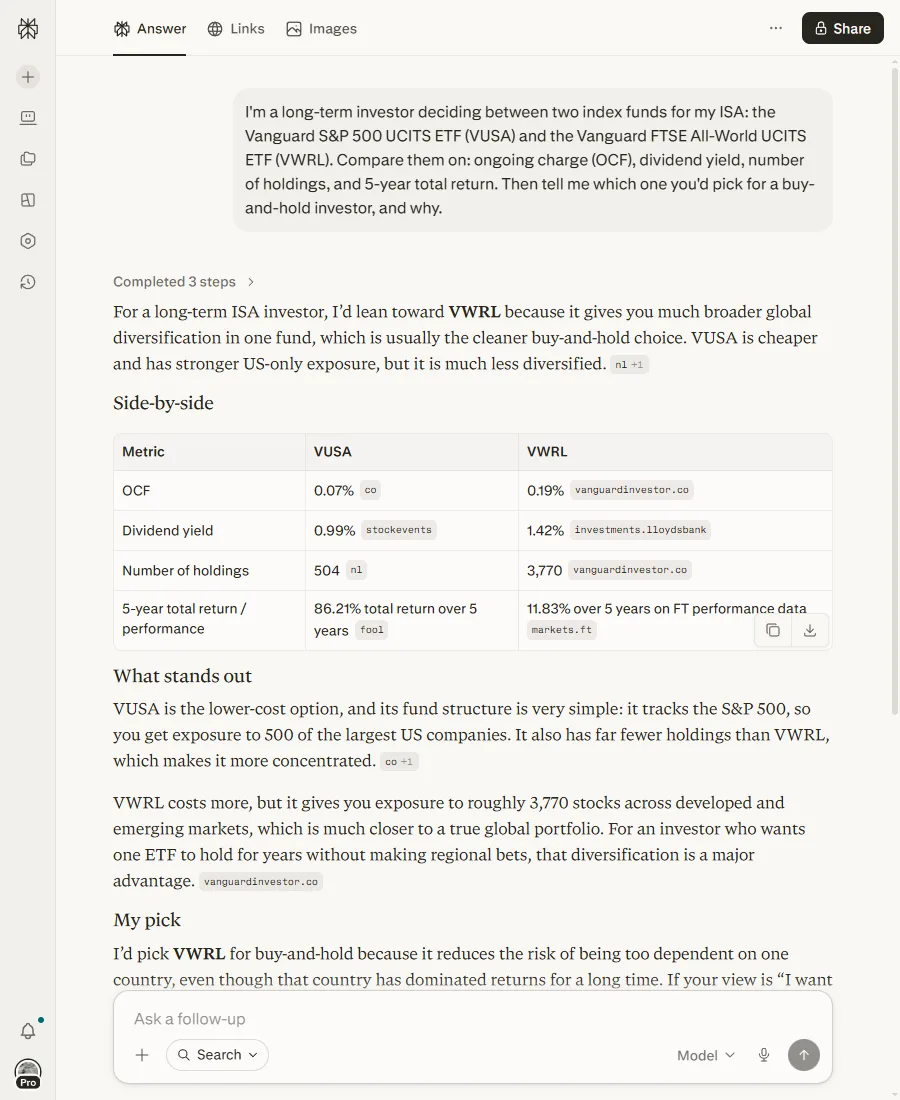
Perplexity. The 11.83% is almost certainly an annual figure mislabelled as a five-year total. The two numbers can’t be read together.
The global fund did not return roughly an eighth of the US fund over five years: they track heavily overlapping markets. What’s happened is that one number is a total over five years and the other is closer to a single year’s growth, pulled from two different sources with two different methods and dropped into the same column as if they matched. To its credit, Perplexity then wrote that the figures “may not be perfectly apples-to-apples.” It just left them in the table anyway, no units, no warning flag, the financial equivalent of labelling a bottle “possibly not water” and leaving it on the shelf next to the water.
The yield was a different kind of wrong
There’s a softer lesson under all this. No two AIs agreed on the dividend yield, and none of them was simply lying. The yield depends on which day you measure it, which version of the fund you’re looking at, and which data provider you trust. There are several defensible answers.
The problem is that each AI gave me one confident number for something that has a spread of right answers, and presented it with the same flat certainty as the fee, which has exactly one. That’s the FILTER step from the Prompt Stack doing real work: separating the facts that are fixed (the published fee) from the ones that move (yield, recent returns). An AI will hand you both in the same tidy row and let you assume they’re equally solid. They aren’t.
What I’d do with this
The fix is small and it’s the same regardless of which AI you use. For any number an AI gives me before I act on it, I ask one follow-up: what’s your source for that figure, and what date is it from? The answer separates the fixed facts from the guesses fast. And for the one number that has a single correct value (here, the fee) checking it against the factsheet takes about thirty seconds and catches the confident misses every time.
That’s the whole method on this question. The AI’s answer reads as a fast, structured first draft that gets you most of the way and points you at the right factsheet, not the final word, because it can’t see the difference between the number it looked up and the number it filled in.
The short version
What worked: All four AIs got the fixed published fee right (except the one that searched the web and still served a stale figure), got the rough number of holdings right, and reasoned sensibly about which fund suits a long-term holder. As a structured first pass, they were useful.
What didn’t: Confident, precise figures that were wrong with no tell: ChatGPT’s US dividend yield (it gave both funds the same figure when they don’t pay out the same), Perplexity’s mismatched returns, Claude’s stale fee despite a live search (logged in the error record). And Gemini silently personalising a “neutral” question from account history, so there’s no single answer to check.
Bottom line: Useful, with a hard caveat. ChatGPT is accurate on the cheap, fixed facts and confidently wrong on the precise, moving ones, and it sounds identical either way. What would change my verdict: an AI that visibly marks which numbers it verified against a named source today versus which it generated, in the answer itself.
So, is ChatGPT accurate? On the fixed facts, yes. On the precise ones, often confidently not, and silently shaped to you when you’re logged in. It’s a quick first draft that points you at the right source, and the thirty seconds you spend checking the one number that has a single right answer is the thirty seconds that makes the rest of it safe to use. If your next question is how often, not whether, I keep a running tally.
Each of those failures (the confident wrong number, the stale figure that survived a live search, the answer quietly shaped to me) has a named type in the nine-mode taxonomy, logged with its dated screenshot.
If you want the receipts, the six most instructive of them are laid out in real AI hallucination examples, caught and dated. And the head-to-head version of this test, every model scored on the same checkable questions, is the Scoreboard. The wider pattern behind this single test is in the State of AI Reliability report: across six checkable finance-and-regulation questions put to six assistants, 36 question-and-model results (N=3; five captured 25-26 June 2026, Copilot on its 18 July join run), there were 3 confident errors and not one outright fabrication, and all three fell on live, moving data while the fixed public-record facts came back clean, the same split this fund test shows in miniature.
Common questions
- Does ChatGPT give confident wrong answers?
- Yes, and that is the core risk. In this test ChatGPT got the published fund fee right but gave both funds the same dividend yield when they do not pay out the same, with the same flat confidence it used on the number it got right. It is accurate on cheap, fixed facts and confidently wrong on precise, moving ones, and nothing in the answer tells the two apart. Ask it for the source and date of any figure, then check the one fixed fact against that source yourself.

Ben tests how far you can trust the main AI assistants, and publishes exactly where they get things wrong. Every post here is a first-hand test with the receipts, including the times a tool simply wasn’t worth the trust. About Ben →
The site tests how far you can trust the main AI assistants, on real decisions. Start with the Prompt Stack for the four-stage framework, free and ungated, or the Bluff Filter for the paste-ready version with a real before and after.