The problem: a sourced ChatGPT answer feels checked because the link works. The fix: open the link and find the specific claim on the page. The payoff: you catch the real-but-wrong source — the one wearing the costume of a footnote without doing a footnote's job.
// On this page
The short answer to whether ChatGPT makes up sources: mostly no, once web search is on. But I asked it a money question and it gave me an answer with a source attached — a real link, to a real government website. I felt reassured — the way you do when a claim comes with a footnote. So I clicked it.
The page loaded. It was a genuine gov.uk page. And it didn’t say what ChatGPT had told me it said.
That gap is the whole post. The worry most people carry about AI sources is that the model invents them — a citation to a study that was never written, a URL that goes nowhere. That happens, and it’s a real failure. But it’s the easy one to catch: a dead link gives itself away. The harder failure is the one I hit here, where the link works, the site is real, and the source still doesn’t back the claim. It’s a footnote that doesn’t take you to the thing it’s a footnote for.
The two ways ChatGPT sources go wrong
There are two separate failures, and most writing on this collapses them into one.
The first is fabrication. The model makes up a source that doesn’t exist. This is the well-documented one — a 2023 study in Scientific Reports found ChatGPT inventing 18% of the references an older version cited, rising to 55% on the weaker model it tested, and other studies put the rate higher still in specialist subjects like medicine. It happens most when the model isn’t searching the web and is reaching back into what it half-remembers from training. You catch it instantly: the link is dead, or the paper isn’t real.
The second is misattribution. The model cites a source that exists — the page is real, it loads, it’s even from an authoritative site — but the page doesn’t contain the claim. The figure is different, the rule has a nuance the page doesn’t mention, or the model stitched a claim together from several places and pinned it on one. This is the failure web search makes more common, not less, and it’s the one that slips past you. The link worked, so you stop checking.
I wanted to see which of these I’d hit if I used ChatGPT the way an ordinary person would — for real money questions, with the answer-with-sources behaviour switched on.
The setup
Two claims, each one checkable against a single named source — a fund fee and an ISA rule. I ran each on ChatGPT (free tier, web search on, temporary chat with memory off — the same way a first-time user gets it), and asked it to cite its sources. Then, for every link it gave me, I did one thing: I opened the page and looked for the specific claim on it.
I graded each cited source on a three-point scale:
- Real and supports — the page loads and the claim is right there on it.
- Real but wrong — the page loads, but the claim isn’t on it.
- Fabricated — the page doesn’t exist, or goes somewhere unrelated.
I ran the same questions through Perplexity and Claude alongside, because the interesting question isn’t “is ChatGPT bad” — it’s whether this is a ChatGPT problem, a web-search problem, or something that happens to all of them on the same question.
// Want the next test in your inbox? Join the newsletter.
Claim one: the fund fee — and why “it lied” is the wrong story
I started with a plain one: the ongoing charge on a popular global index fund (the Vanguard FTSE All-World ETF, ticker VWRL — a fund that holds a slice of thousands of companies worldwide, the kind of thing a lot of people hold in an ISA). What’s the annual fee?
ChatGPT said 0.19%. It cited four links, all on Vanguard’s own domains, and noted the figure used to be 0.22% before Vanguard cut it. I opened the links. Real Vanguard pages. The figure checked out.
Then I ran the same question through Perplexity and Claude. Both also said 0.19%. Both cited real Vanguard pages. Claude added — unprompted — that you’ll still see the old 0.22% floating around in stale sources, and flagged it.
So here’s the honest result, and it matters: on this question, nobody made anything up. Three tools, the correct number, real sources from the fund provider itself. If I’d set out to write a post called “AI invents your fund fees,” this claim kills it on the first try. Which is the point — the scary version of this story isn’t the true one. The number was fine. I had to keep looking for where the cracks were.
The scary version of this story — AI invents your sources — isn't the true one. The real failure is quieter, and it survives the click.
Claim two: the ISA rule — where the source went wrong
The cracks showed up on the next question. This is the one the whole post is built on, so I’ll be precise about it.
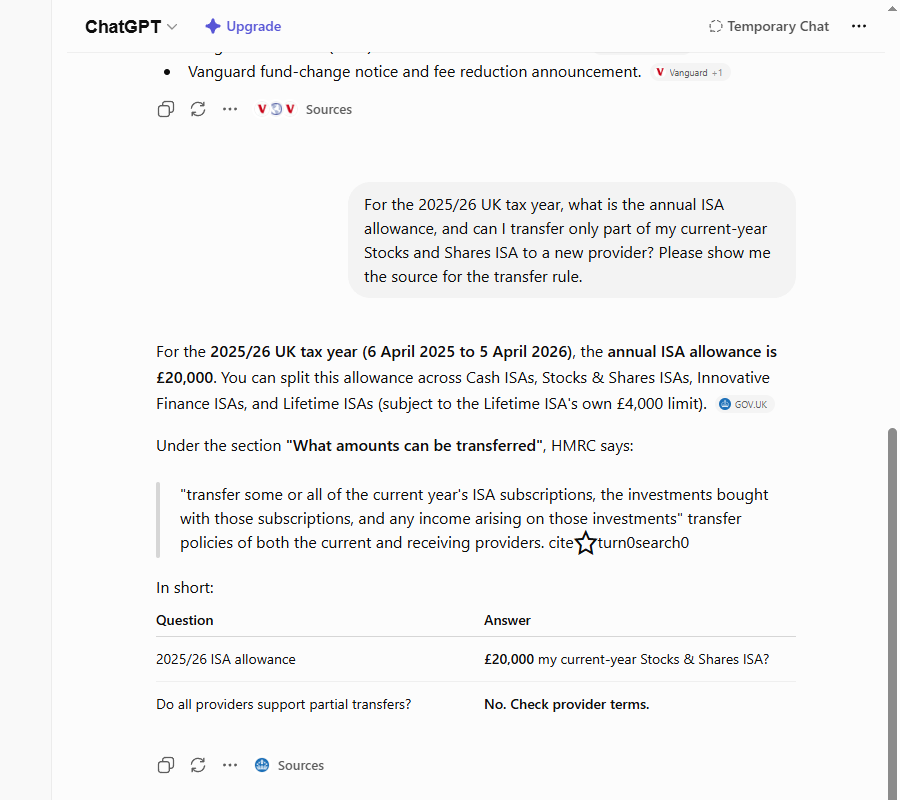
I asked about a rule a lot of UK savers need: an ISA is a tax-free savings or investment account, with a £20,000-a-year limit, and the question was — if you’ve paid into a Stocks and Shares ISA this tax year, can you move just part of it to a new provider, or do you have to move the whole lot? I asked ChatGPT for the answer and the source for the transfer rule.
It got the answer roughly right in the prose — yes, partial transfers are now allowed, since a rule change in April 2024. Then it gave me its source: a gov.uk link.
I clicked it. The page loaded. It was a real, current gov.uk page. And it was the wrong page — it was the page about what happens to your ISA if you move abroad or die. Nothing on it about transferring part of your current-year money to a new provider. The rule ChatGPT was citing lives on a different gov.uk page entirely, the one titled “Transferring your ISA,” which says in plain words: “You can transfer all or part of the savings in your Individual Savings Account (ISA) from one provider to another at any time.”
That’s the real-but-wrong grade, exactly. The citation isn’t fabricated — gov.uk is as authoritative as a UK source gets, and the link is alive. But it points at a page that doesn’t hold the rule. If you’d clicked it to check the answer, you’d have landed on an official government page, felt reassured by the domain, skimmed, and never noticed it was about something else. The footnote loaded. It just wasn’t a footnote for this.
Here’s what makes it a fair test rather than a pile-on: not every tool did this. I gave Perplexity the same question on the same day. It cited the correct gov.uk page — “Transferring your ISA” — and quoted the actual line that contains the rule. Claude searched, flagged that the sources disagreed, reconciled them, and landed on the right rule too. So this isn’t “AI can’t cite gov.uk.” It’s that one tool, on one run, attached the right answer to the wrong page — and presented it with the same confidence it used when it got the fund fee exactly right.
That’s the part worth sitting with. The misattribution doesn’t look any different from a good citation. There’s no warning colour, no lower confidence in the wording. The source that backs the claim and the source that doesn’t are rendered identically.
Why web search makes this trickier, not easier
You’d think turning on web search would fix all of this. In one way it does — it kills most outright fabrication, because the model is pulling from pages that exist. The fund-fee question shows it: real sources, real number.
But it introduces the subtler problem at the same time. When there’s no sources button, you already know to be sceptical — the model is clearly working from memory, and you treat the answer accordingly. When there is a sources button, with tidy link pills under the answer, it feels checked. The presence of citations does the reassuring; almost nobody opens them. And that’s precisely the gap the misattributed source lives in.
It’s not just me finding this. The Tow Center for Digital Journalism ran 200 queries asking ChatGPT’s search to identify where news quotes came from, and found it wrong or misattributed in over three-quarters of cases — real URLs, wrong attribution. That was a different task (tracing quotes, not sourcing a fund fee), so I won’t stretch the number onto my finance test. But the shape is the same as what I hit: web search returns you a real page, and “real page” and “page that backs the claim” turn out to be two different things.
This is one specific shape of a broader pattern I keep running into — the model inheriting confidence from a source’s format without checking whether the source earns it. I’ve written about that as borrowed certainty; the misattributed citation is one of its cleaner examples.
The 10-second check
The fix costs almost nothing, which is the only reason it’s worth writing down. When ChatGPT gives you a sourced claim that matters — a fee, a rule, a date, a number you’re about to act on — open the link and look for the specific claim on the page. Not “does the link work.” Does the page actually say the thing.
For the fund fee, that’s searching the page for “0.19”. For the ISA rule, it’s reading the heading and asking: is this page even about transfers? Ten seconds, and the wrong-page citation falls apart the moment you look, because the page is about moving abroad and you’re asking about transfers.
I do this now by reflex, and it’s changed which answers I trust. A sourced answer I haven’t opened is, to me, an unsourced answer with better presentation. The ISA question in this post is part of a broader pattern: I ran four AI tools through a set of UK ISA questions, and the partial-transfer rule was exactly where the tools split — the ones that searched got it right; the ones working from memory gave the abolished rule. Perplexity, for what it’s worth, builds its whole interface around making this check easier, putting the citation next to each sentence rather than in a pile at the end — though as I found in a longer look at Perplexity for investment research, that helps most when the topic is well-covered enough to have good sources in the first place.
Field Report
What worked: With web search on, ChatGPT cited real, live pages on every question, and got the fund-fee number exactly right with sources from the fund provider itself. Outright fabrication didn’t show up in this test.
What didn’t: On the ISA transfer rule, it cited a real gov.uk page that doesn’t contain the rule — the right answer pinned to the wrong page, rendered with the same confidence as a correct citation. Perplexity, given the same question the same day, cited the correct page.
Bottom line: Useful, with one habit attached. The honest finding isn’t that ChatGPT invents sources — mostly it doesn’t, once web search is on. It’s that a real, working link is not the same as a source that backs the claim, and the difference is invisible until you open the page. What would change the verdict: if the sources button reliably linked to the exact page holding the claim, the 10-second check would stop earning its place. It doesn’t yet.
The most dangerous source isn’t the one that’s obviously made up. It’s the one that loads — wearing the costume of due diligence — and still doesn’t say what it was cited to say. That one survives the click. The only thing that catches it is reading the page it sent you to.

Ben tests ways of getting reliable answers from AI on his own investing — documenting what each model got wrong, what each one caught, and the prompts that survived the cuts. About Ben →
The site runs AI on real investing decisions. Start with the Prompt Stack for the four-stage framework, or the Field Guide PDF for the condensed version — free, no email.