- Problem
- every Perplexity review online is a glowing feature tour with no failure test.
- Fix
- I scored it on real names across four jobs.
- Payoff
- it's useful where a name has enough independent coverage to cross-check, and dangerous where it doesn't — the deciding factor is source coverage, not company size.
// On this page
A tool once told me one of my own holdings had nearly ceased to exist. Revenue of “$6K”, it said — “down 99.8% from prior year.” The company had not collapsed. It had grown. The only thing that had collapsed was the denominator: the filing reported in thousands, so the real number was $6.1 million. The tool had read the small print and skipped the two words at the top of the page that change everything. The tool was Perplexity.
And here’s the honest part — on the same week, on a household name like Meta, it gave me one of the better earnings summaries I’ve seen out of any AI tool. Both of those are true at once, which is the whole problem with the question “is Perplexity good for investment research?” The reviews that rank for that search are, every one I could find, a glowing tour of the features. None of them tests what happens when the tool gets a real filing wrong. So I did. Here’s what works, what breaks, and the single thing that decides which one you’ll get.
How I tested Perplexity for investment research
Everything below comes from real sessions on my own Perplexity Pro account, run across May and June 2026. No paraphrasing from memory — where I quote Perplexity, that’s what it said, captured at the time. I tested four jobs an investor asks a tool to do: look up figures on big well-known companies, look up figures on smaller obscure ones, summarise earnings calls, and reason through a live trade.
One thing worth knowing up front. Perplexity isn’t a model of its own. It’s a layer that retrieves from the web and routes your question to whichever underlying model it judges best. In the sessions I ran for this post the footer showed Claude Sonnet as the model doing the work, though Perplexity’s “Best” setting can route to other models and doesn’t always say which. That matters, because it means Perplexity’s strength is the retrieval and citing, not the reasoning underneath, and its mistakes look different from a tool making things up out of training data. They come from what it reads, not what it invents.
What “passing” looks like, per job: the right figure, from a named source, with honesty about anything it couldn’t find.
Where it earns its place: well-covered names
Start with the good news, because it’s real. Ask Perplexity about a company that fifty analysts cover and a dozen data sites track, and it’s fast, sourced, and rarely wrong.
I asked it to summarise Meta’s last two earnings calls — what management said about getting to profitability, and what they dodged. It came back with a proper piece of work: both calls covered, the right revenue and profit figures, and an analyst-by-analyst breakdown of who pushed on what. It named Brian Nowak at Morgan Stanley asking about long-term AI revenue (“monetisation details will become clearer as products roll out”), Eric Sheridan at Goldman on compute capacity, Douglas Anmuth at JPMorgan on free cash flow. Then it did something I didn’t expect — it spotted a pattern across both calls and called it “the Recurring Blind Spot”: management answering what they’re building and why it matters, but deflecting every time analysts asked when the AI spending pays off. Twenty-eight sources, all named.
On the quick factual stuff it’s equally solid. In a separate run I fired eight rapid questions at it — NVIDIA’s close, the Bank of England base rate, whether the S&P 500 yields above 3%, Microsoft’s full-year revenue. All correct, all cited to primary sources where they existed: the Bank of England’s own site for the rate, NVIDIA’s newsroom for the data-centre figure. This is the job Perplexity was built for, and it does it well. If I want a cited current snapshot on Meta, Apple or NVIDIA before scanning a results release, it’s faster than searching by hand and it shows its working.
Ask Perplexity about a company that fifty analysts cover and it's fast, sourced, and rarely wrong. Ask it about one that nobody cross-checks, and a single misread has nothing to catch it.
So why does the same tool turn a growing company into a near-corpse?
// Want the next test in your inbox? Join the newsletter.
Where it breaks: thinly-covered names
The Meta summary worked because Meta is drowning in independent coverage. Get a figure wrong on Apple and eighty analyst price targets, a stack of Morningstar reports and a dozen data aggregators all contradict you instantly. The error can’t survive. There’s a safety net under every number.
Now take BMNR — a smaller company I trade, US-listed but barely covered. I asked Perplexity for its revenue. It read the company’s annual report, saw “$6,095,” and reported “$6K.” The report, like most company filings, states its figures “in thousands” right at the top — so $6,095 means $6.1 million. Miss that one convention and you’re out by a factor of a thousand. Worse, Perplexity didn’t stop at the wrong number. It built a story on top of it: revenue “down 99.8% from prior year,” a near-total collapse. Confident, fluent, and completely false.
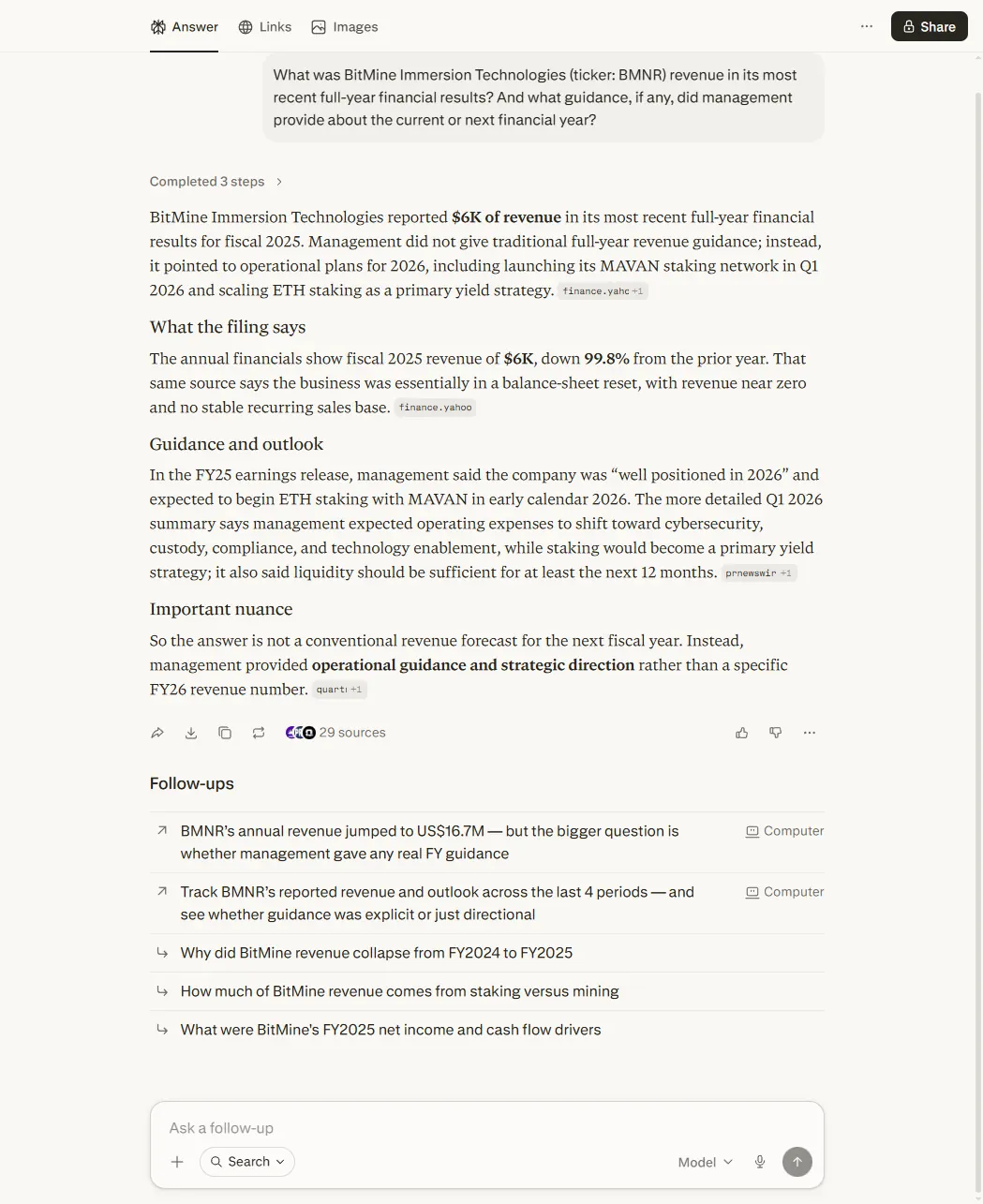
A retail investor who asked that question and didn’t know to check the filing would have walked away believing a healthy business had nearly gone to zero. That’s not a rounding slip. It’s a decision-affecting error dressed in the same confident, well-cited prose as the correct Meta answer — and there was no second source to catch it, because on a name this obscure there barely is a second source.
For honesty’s sake: when I re-ran this exact test on 14 June 2026 — part of the full four-tool comparison this audit sits under — Perplexity returned the correct $6.1 million figure. The failure was real, screenshotted and dated, and AI tools change, which is exactly why I date every verdict and log the failures publicly on the lessons page. But the mechanism doesn’t change just because one run came good. The risk is structural: where coverage is thin, the safety net is missing.
It’s tempting to read that and conclude “Perplexity is fine on big companies and bad on small ones.” That’s nearly right, and it misses the real variable. The week after the BMNR miss, I tested it on a small UK company — Next Fifteen Communications, an AIM-listed group most people have never heard of. By size, it’s exactly the kind of name where Perplexity should fall over.
It didn’t.
I’m researching a small UK-listed company: Next Fifteen Communications (NFC.L). What was its revenue and adjusted EBITDA for its most recent full financial year, and what guidance has management given for the current year?
“For Next Fifteen Communications’ most recent full financial year, revenue was £569.7m and adjusted operating profit was £107.4m […] For the current year, management has said performance is expected to be broadly in line with market expectations, which the company has published as net revenue of £450m and adjusted operating profit of £66.6m for FY26. […] I couldn’t find a clear company-published adjusted EBITDA headline in the retrieved sources for FY25, so I used the company’s reported adjusted operating profit figure, which is the closest recurring earnings measure highlighted in its results materials.”
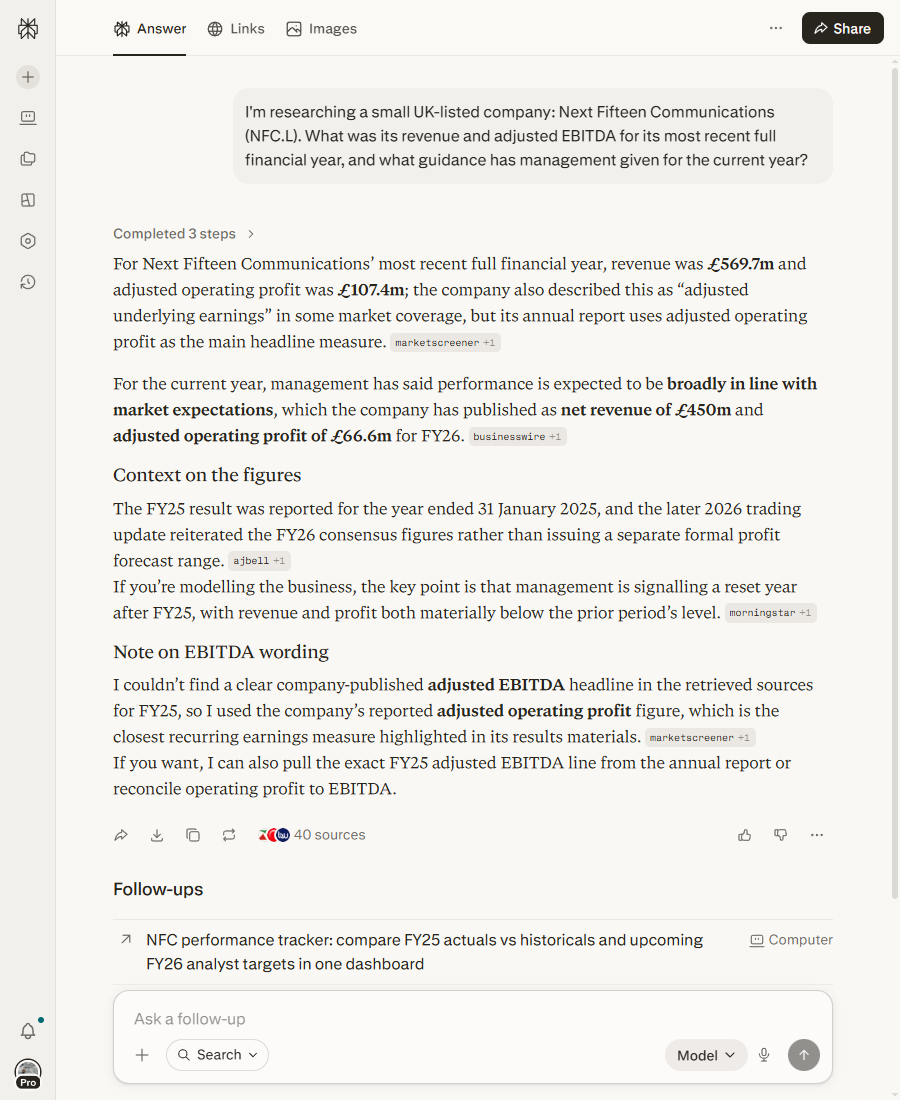
Two things stand out. First, it returned specific figures with named sources, got the unusual January year-end right, and correctly drew the line between official guidance and the consensus number management had simply endorsed. Second, the part the BMNR answer was missing: when it couldn’t find the published adjusted EBITDA figure I’d asked for, it said so and substituted the nearest real measure rather than inventing one.
That single sentence ("I couldn't find a clear company-published adjusted EBITDA headline") is the difference between a tool you can work with and one that quietly leads you off a cliff.
And the figures held up. I checked the headline numbers against the company’s actual full-year results: revenue of £569.7m and adjusted operating profit of £107.4m are both correct, and the year-on-year reset it described is real. The consensus figures it gave for the year ahead (around £450m of net revenue, £66.6m of adjusted operating profit) are within a whisker of the company’s own published consensus. So on a small, obscure UK name it got the answer right and was honest about the one figure it couldn’t find. That is the opposite of the BMNR run.
NFC.L isn’t bigger or better-known than BMNR. It’s smaller and more obscure. What it had was enough independent secondary coverage — AJ Bell, Morningstar, a couple of market-data sites — for Perplexity to cross-check itself. Reliability tracks coverage, not company size. Where a name is well-covered, the tool has redundancy and gets it right. Where coverage is thin, a single misread has nothing to correct it, and the wrong answer arrives wearing the same confident face as the right one.
Earnings calls: depends entirely on the name
This is the same coverage rule playing out on a different job. On Meta, the earnings summary was substantial — named analysts, a real pattern across two calls, genuine synthesis. When I asked the same question about a thinly-covered name, the tool told me, straight out, that it can’t: on BMNR it opened with “full earnings call transcripts for BMNR are not accessible through publicly available sources in my search results” and gave a thinner answer built from secondary summaries.
To its credit, that’s the honest response. Better to admit the transcript isn’t there than to confect one. But it sets the ceiling: Perplexity will tell you what management said on a well-covered name, and it won’t tell you what they implied. In a separate test I ran on a Meta CFO comment about spending plans, it caught the obvious hedges and noted where specific figures were missing, but it read past a subtler signal in the word “underestimate” — a one-directional framing that gestures bullish without committing to anything. Catching that needs a tool you’re asking to reason, not retrieve. For reading between the lines, the right tool is something built for analysis, and I’ve written separately about Claude doing exactly that on earnings calls.
Live data and options: honest, but not a broker
I asked for the current bid, ask and delta on an Apple call option. Perplexity went and looked, found stale data on Yahoo Finance — a bid and ask both sitting at zero — and told me exactly that: the quote was stale and illiquid, not real pricing. It did not make up a number to fill the gap. That’s the right answer, and it’s worth crediting, because it’s a place other tools fall down badly. (Honest options data has nothing to do with company size: it’s about whether a live feed exists at all, and through a chat tool it usually doesn’t.)
For the reasoning side, I gave it a real covered-call setup — 200 shares of Meta, a strike about 5% above the current price, 30 days out — and asked for a verdict. It produced something useful: a clear “sell one contract, not two,” a 30-day expected-move figure of around 5.7% pulled from a named options site, and a sensible reason to keep half the holding uncapped. The catch is the same as everywhere else. That analysis is retrieved from across the web, not reasoned from first principles. For a “walk me through this setup” question, the distinction may not bother you. For “stress-test my thesis and tell me what I’m missing,” it should.
Perplexity isn't a broker and it isn't an analyst; it's a very fast, very honest librarian.
On options specifically, I’ve laid out where these tools fall short.
One more gap, for UK readers
If you invest through an ISA in London-listed shares, there’s a specific hole worth knowing. I tested Perplexity’s finance pages on Unilever (ULVR.L) and Apple side-by-side. The price, the chart and the earnings-call highlights all worked fine on the UK side. But the analyst layer — consensus rating, named broker price targets, the professional research reports — came up empty for Unilever, where the Apple page was stuffed with them. You can see what the numbers are, not what the professionals think of them. Which free tool wins depends on the name and the job, and I keep a running view of the best free AI tools for stock research.
What to use it for
| Job | Verdict |
|---|---|
| Quick fact lookup — price, rate, revenue on a big well-known company | Useful |
| Earnings summary on a well-covered company | Useful |
| Revenue and figures on a smaller, thinly-covered company | Not reliable — check the filing |
| Index-fund comparison (fees, yield, holdings) | Conditional — the table’s handy, verify the return figures |
| Live options pricing | Conditional — honest about stale data; not a broker |
| Covered-call setup reasoning | Conditional — practical, but retrieved not reasoned |
| UK London-listed shares: price and transcripts | Conditional — works; analyst consensus missing |
| What management implied (reading between the lines) | Weak — it reports, it doesn’t infer |
One more honesty flag, because it bears on every table Perplexity hands you. When I asked it to compare two index funds (Vanguard’s VUSA and VWRL), it produced a clean side-by-side — fees, yield, holdings, all sensible — then dropped a five-year return figure into the table that was almost certainly an annual number mislabelled as a five-year total. To its credit, the prose underneath warned the figures came from different sources and might not be comparable. But the wrong number stayed in the table. Read the table, skip the small print, and your comparison is badly distorted. When Perplexity stitches one table from several data providers, treat the cells as a starting point, not a finding.
Field Report
What worked: Fast, well-sourced answers on well-covered companies — the Meta earnings summary, with named analysts and a real cross-call pattern, was a proper piece of work. It’s honest about stale data and about what it can’t find, and it cites primary sources where they exist.
What didn’t: On a thinly-covered name it misread a filing by a factor of a thousand and built a confident false collapse on top of it. It reports what management said but not what they meant, and it’ll leave a wrong figure inside an otherwise-tidy table.
Bottom line: Conditional — for well-covered names. The deciding factor is source coverage, not company size: where a name has enough independent coverage to cross-check, Perplexity is one of the fastest first passes going. Where coverage is thin, a single misread has nothing to catch it. The verdict flips the day Perplexity starts validating filing conventions on smaller names (checking whether a number is stated in thousands). Not yet.
What I actually do: I open Perplexity first for the quick, cited snapshot on any household name, and I trust it for that. The moment a name is obscure — a smaller US company, anything on AIM, anything where I can’t picture three sources that would catch a mistake — I treat its answer as a lead and go and read the filing myself. The skill isn’t avoiding the tool. It’s knowing which question you’ve just asked it, and whether there’s anything standing behind the answer to catch it if it’s wrong. Perplexity is one of four tools I’ve put through this on real trades — the full audit of what each one gets wrong is the wider view. If you want the discipline I run every answer through, it’s the Prompt Stack.

Ben tests ways of getting reliable answers from AI on his own investing — documenting what each model got wrong, what each one caught, and the prompts that survived the cuts. About Ben →
The site runs AI on real investing decisions. Start with the Prompt Stack for the four-stage framework, or the Field Guide PDF for the condensed version — free, no email.