- Problem
- people assume turning on web search makes an AI answer more trustworthy.
- Fix
- check what it actually retrieved, because web search is only as good as the source that happened to rank.
- Payoff
- you stop trusting a confident answer that's quietly built on a hobby blog instead of the official guidance.
// On this page
Does web search make AI more accurate? Everyone assumes it does, so last week I asked four AI tools the same question to check: how long can I safely keep cooked chicken in the fridge? Two of them ran a web search before answering. Two worked from training data alone. I wanted to see whether the ones reaching out to the live web gave a better answer than the ones that didn’t.
They all gave the same number — 3 to 4 days. So on the face of it, web search made no difference at all. But that’s not quite what happened. The model that searched the web pulled its answer from two US food blogs and led with the American figure. It knew where I was — it said “since you’re in Newcastle” — and it still put the UK food safety guidance second. The Food Standards Agency says eat cooked leftovers within 2 days, and that turned up as a secondary note after the confident 3-to-4-day headline, framed as the stricter option rather than the answer. The tools that didn’t search just gave me the US number flat, with no sign there was a UK answer at all.
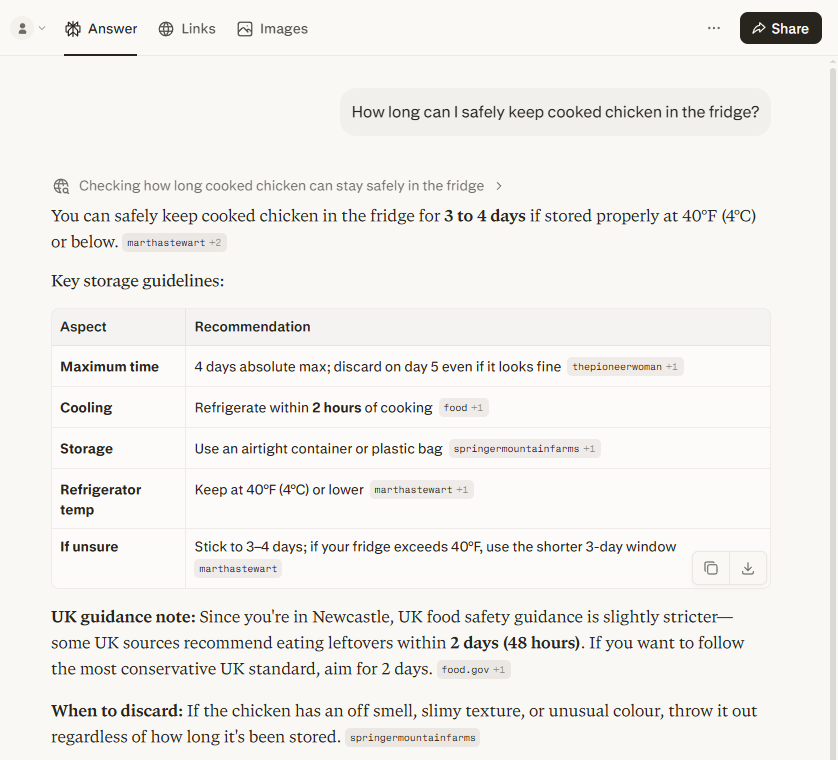
This is the pattern I keep running into. Adding web search to an AI is sold as a straight upgrade: real-time information, cited sources, fewer made-up answers. The receipts say it’s more complicated. Web search doesn’t reliably make an AI more accurate. It moves where the unreliability lives — and it doesn’t tell you it’s done that.
The ISA test: search was the thing that got it right
The cleanest case for web search came from a different test entirely — one I’ve written up in full, so I won’t re-run all of it here. I put a set of UK ISA questions to the same four tools. An ISA, for anyone arriving from the AI side of this site, is a UK tax-free savings account.
On the basics, all four were fine. The interesting one was a question about partial transfers of this year’s ISA money — a rule that was changed in April 2024. Claude and Gemini searched the web before answering and gave the correct, current rule. Claude even said, unprompted, that ISA rules had changed recently and that it wanted to check rather than rely on memory. The two tools that answered from training alone gave the rule that was abolished over a year ago, stated as if it were still true.
That’s web search earning its place. ISA rules live on gov.uk and a wall of bank and comparison-site pages that all say the same correct thing. When that’s what gets retrieved, the search drags the answer towards the truth. The model that admitted its own knowledge might be stale is the one that got the changed rule right.
The model that admitted its own knowledge might be stale is the one that got the changed rule right. Searching wasn't a flourish — it was the mechanism.
One honest limit: this is one question, and “training data is the unreliable bit” isn’t a rule either. Sometimes training is plenty. Which is the next test.
The passport test: search added a receipt, but didn’t change the answer
I gave all four tools a slightly fiddly passport question — a UK passport issued in March 2016, a trip to Spain in October 2026, does it still work? The catch is the post-Brexit ten-year rule: a passport over ten years old on the day you arrive gets turned away, even if the printed expiry date is months off.
All four got it right. They all caught the ten-year trap and told me to renew. The three that searched the web cited gov.uk and Schengen pages to back it up. ChatGPT, with no search, got there from training alone — it even opened with “Short answer: yes” and then corrected itself mid-answer to a clear no, which was a slightly nerve-jangling way to be right, but right it was.
So here web search did something real but smaller. It didn’t change the answer — training already had the answer. What it added was provenance: a visible source you could click and check. That’s worth having. It’s just not the same as making the answer correct, and it’s easy to mistake one for the other. A cited source feels like proof. Sometimes it’s only decoration on an answer the model already knew.
// Want the next test in your inbox? Join the newsletter.
The oven test: search reached for the wrong kind of expert
Then the one that complicates the picture. I asked a plain domestic question: a recipe says bake at 180°C fan, my oven has no fan, what do I do? The settled kitchen answer is to add about 20°C — so 200°C — and leave the time roughly alone.
The three tools answering from training gave that: 200°C, same time, with one adding that you’d start checking a few minutes early. Perplexity, searching the web across fifteen sources, gave the 200°C bump too — and then added that I should bake about 25% longer, citing among its sources an appliance-repair blog.
I want to be careful here, because this is where it would be easy to overclaim. The time question is properly contested. Plenty of cooks do extend the time a little, and I’m not going to tell you the repair blog is wrong about ovens. What I can tell you is what the search did: it reached for a lower-authority source — a site about fixing appliances, not about baking — and let its advice diverge from what every cooking-led answer gave me. The extra advice arrived in exactly the same calm, confident tone as the part everyone agrees on. Nothing on screen said “this next bit comes from a repair forum, take it or leave it.” Confident delivery is flat. Source quality underneath it is not.
The pattern: web search is only as good as what ranks
Put the four together and the shape is clear enough.
- ISA rules — gov.uk and the banks rank. Search helped.
- Passport rules — gov.uk ranks. Search backed up an answer training already had.
- Oven settings — a repair blog ranked alongside the cooks. Search added noise.
- Cooked chicken — US food blogs ranked above the UK regulator. Search gave a UK user a US-sourced answer.
The variable isn’t whether search is on or off. It’s what happened to rank on the open web for that exact question — and whether the thing that ranked is actually an authority on it. Government rules pull up government sources, so search reinforces the right answer. Folk-knowledge questions pull up blogs and forums, so search can hand you a minority view delivered with the same certainty as the official line.
I’ve seen the same move in a far more expensive context. Testing AI on a live options trade, I watched ChatGPT give a precise-looking earnings date sourced from a financial-data site, with no hint that reporting dates move or that the page might lag the company’s own calendar. The certainty wasn’t earned by checking — it was borrowed from how official the source looked. Same pattern, bigger stakes: web search hands the model a real source, and the model wears its apparent authority without asking whether it deserves it for this specific claim.
And none of this shows up on your screen. Perplexity searches the web by default — many people don’t know that — and when it cites a hobby blog it does so in exactly the same font as when it cites a regulator. The thing you most need to know to judge the answer, which is how good the source is, is the one thing the interface doesn’t tell you.
The ten-second defence
None of this is a reason to stop using web-search AI. It’s a reason to read what it gives back a little differently.
When the answer matters, I look at what it actually retrieved, not just whether it searched. The questions take ten seconds: Did it cite a source? What kind of source — the official body, or a blog that turned up on page one? And for anything that differs by country, like food safety or tax or travel rules, is the source from the right country? A UK user getting a US food blog is a wrong answer wearing a citation.
It also pays to know which tools lean on the live web and which lean on training, because the failure modes differ — I go through what each free tool does in the free-tools audit. The honest one-line version: for anything with a dated, official source (tax rules, passport rules, government guidance), a web-search tool is worth using, and worth asking to name the rule and the date it took effect. For folk-knowledge questions where blogs dominate the results, treat the answer with the same scepticism you’d give the first result on Google. Because under the bonnet, that’s often exactly what it is.
Field Report
What worked: On ISA and passport rules, web search pulled answers towards gov.uk and got the current rule right — including a changed rule that training-only tools got wrong.
What didn’t: On oven settings and UK food safety, web search led with lower-authority sources — a repair blog, US food blogs — and either added noise or handed a UK user a US answer. The delivery was equally confident in every case.
Bottom line: Useful, with a catch. Web search doesn’t make AI more accurate across the board; it changes the failure mode, and the new failure is invisible because the AI never tells you how good its source is. Four tests across four question types is a pattern worth checking for yourself, not a law — and it would shift if these tools started ranking sources by authority and showing you that they had.
These were four everyday questions, the kind you’d actually type in before doing something. Not one of them was answered “more accurately” just because the web was switched on. The web being on only decided where I had to look to check the answer — and that’s the part worth keeping in your head before you act on what comes back.

Ben tests ways of getting reliable answers from AI on his own investing — documenting what each model got wrong, what each one caught, and the prompts that survived the cuts. About Ben →
The site runs AI on real investing decisions. Start with the Prompt Stack for the four-stage framework, or the Field Guide PDF for the condensed version — free, no email.