- Problem
- every AI earnings comparison tests whether the tool can read the numbers.
- Fix
- I tested both tools on the harder job — reading the management hedge language — on a real transcript, same day.
- Payoff
- Claude catches the signal without being asked; ChatGPT gets there too, but only once you give it the structure.
// On this page
Meta reported strong revenue. The stock fell about 8%. The reason wasn’t in the numbers — it was in three sentences of prepared remarks, where the company’s finance chief described how much it planned to spend on AI infrastructure (its “capex”, short for capital expenditure — the money a company sinks into things like data centres). Revenue beat expectations. The shares dropped because management signalled it would spend far more than analysts had forecast, and gave no timeline for when that spending would pay off.
So on results morning, the most useful thing you can ask an AI isn’t “what were the numbers.” It’s “what did management commit to, what did they hedge, and what did they carefully avoid saying.” That’s the job I wanted to test. I pasted the same passage into ChatGPT and Claude, on the same day, and asked both the same plain question. One gave me the figures. One caught the word that mattered.
This is a narrow ChatGPT vs Claude for earnings call analysis test, not a general comparison of the two tools — the cluster pillar runs that across five research dimensions. One question: reading the prepared remarks for what was said, hedged, and left out. Which tool to open first for that, in the twenty minutes after a release lands.
How the test was run
Four dimensions, same Meta Q1 2026 transcript, fresh conversations on each tool, same day (18 June 2026). I saved every output verbatim and screenshotted the ones that decide the verdict. The source passage is Susan Li’s capex guidance, taken from the public transcript — the verbatim text is below.
The models, logged exactly as the apps showed them:
- Claude — Opus 4.8 High, Max plan, on all four dimensions
- ChatGPT — free plan, GPT-4o for dimensions 2 and 3
One honest snag I’m not going to bury. ChatGPT’s free plan hit its GPT-4o message cap partway through, so dimensions 1 and 4 ran on a weaker fallback model — the app wouldn’t say which, only that it was “a less powerful model” until the quota reset. That means the head-to-head on those two is not a same-tier comparison, and I’ve flagged it at each. The dimension that carries the verdict — the unprompted read — ran on GPT-4o for ChatGPT and Opus 4.8 for Claude. That one is clean.
What “winning” looks like here: catching what management implied without committing to it. Not the dollar figures — both tools get those. The word that moves the stock. (For the separate question of which tool is best on the free tier when you can’t pay for either, I’ve written that up in the free AI tools round-up.)
The passage, pasted verbatim into both:
“Our experience so far has been that we have continued to underestimate our compute needs even as we have been ramping capacity significantly… We anticipate 2026 capital expenditures, including principal payments on finance leases, to be in the range of $125 to $145 billion, increased from our prior range of $120 to $135 billion… If we end up not needing as much as we anticipate, we can choose to bring it online more slowly or reduce our spending in future years.”
Dimension 1 — Does it stay inside the document?
The test: paste the passage with one instruction — “work only from the pasted document, do not search the web” — then ask what the company committed to. The thing being checked is discipline. A tool that goes off to fetch external data is doing a different job than the one you asked for. (Perplexity fails this one badly in the broader earnings test — ten web searches when told to read only the passage in front of it.)
Both ChatGPT and Claude stayed inside the document. Neither invented a consensus figure, neither pulled in outside quarterly data. ChatGPT returned a tidy two-sentence extraction: no fixed commitment, a $125–145 billion anticipated range, flexibility to spend less. Correct, and exactly as far as it went.
Claude stayed in the document too, but couldn’t help itself — even here, asked only to extract, it noted “the upside is implicitly open-ended given the framing that they’ve ‘continued to underestimate’ needs,” and added that “the trap in the question is the word ‘commit’.” It was already reading the language when all I’d asked for was the facts.
A draw on discipline, then — both passed. With the caveat that ChatGPT was on its weaker fallback model here, so this isn’t a fair read on what GPT-4o would have done. I’ll call it a draw and move on rather than manufacture a winner.
// Want the next test in your inbox? Join the newsletter.
Dimension 2 — Catching the hedge without being asked
This is the one. Same passage, but the bare question — “what did the CFO commit to on capital expenditure?” No instruction to look for hedges. No structure. Just the question most people would type.
ChatGPT gave a competent extraction. It opened: “The CFO didn’t make a hard, fixed commitment to spend a specific amount—rather, they set an updated expected range and emphasized flexibility.” It correctly caught the downside escape clause — “if demand doesn’t materialize, they can slow deployment or reduce future spending” — and netted out with a clean bottom line: committed to a planning range, retained full discretion to scale it down.
What it never did was use the word “underestimate.” The upward signal — the bit where the CFO tells you, in passing, that the real number could land above the top of the range — went straight past it, the way a distracted intern skims to the dollar figure and stops reading.
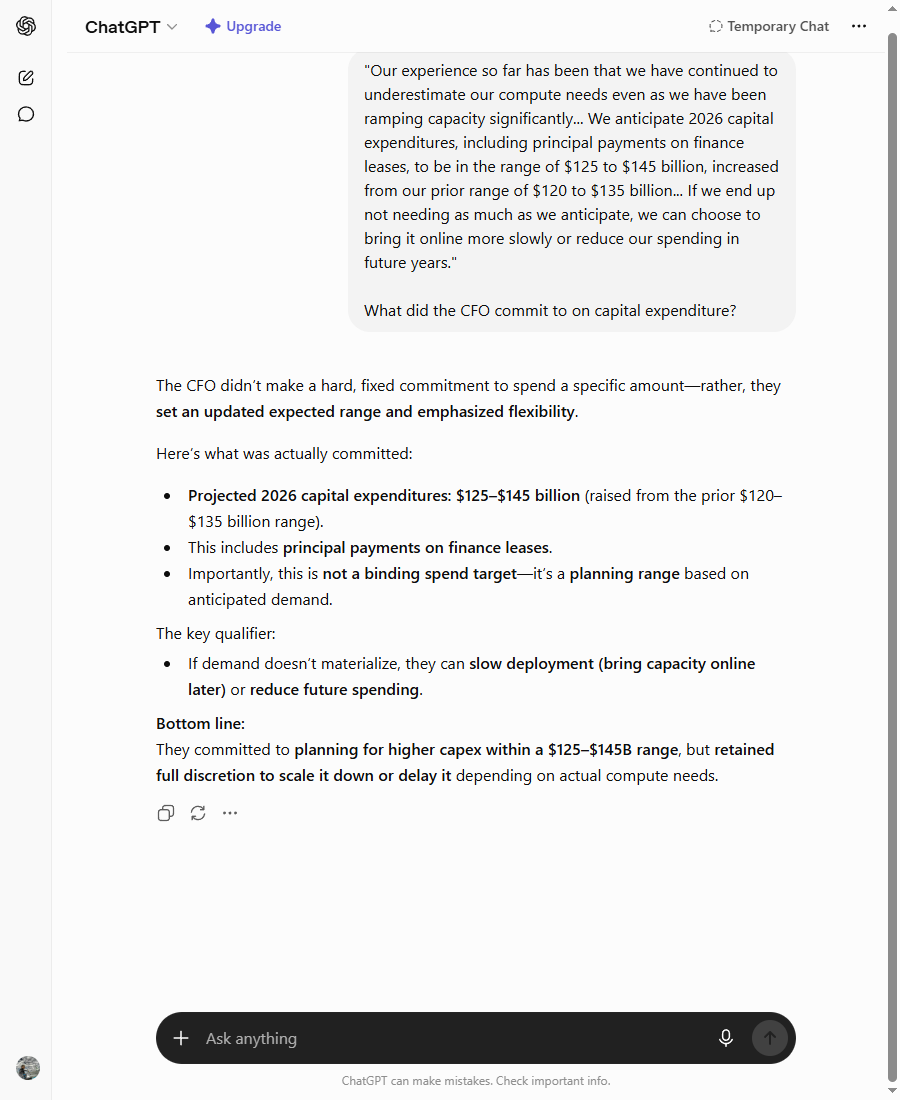
Claude, given the identical question, opened with a sentence I’d have been pleased to write myself: “Read literally, the CFO committed to very little.” Then it did the thing ChatGPT didn’t. Unprompted, it flagged the word: “‘we have continued to underestimate our compute needs’ is a soft warning that the real number could land above the range, not just within it.” It caught the downside escape clause too. And it reframed the whole statement — “the only genuine commitment is to a higher trajectory of intent.”
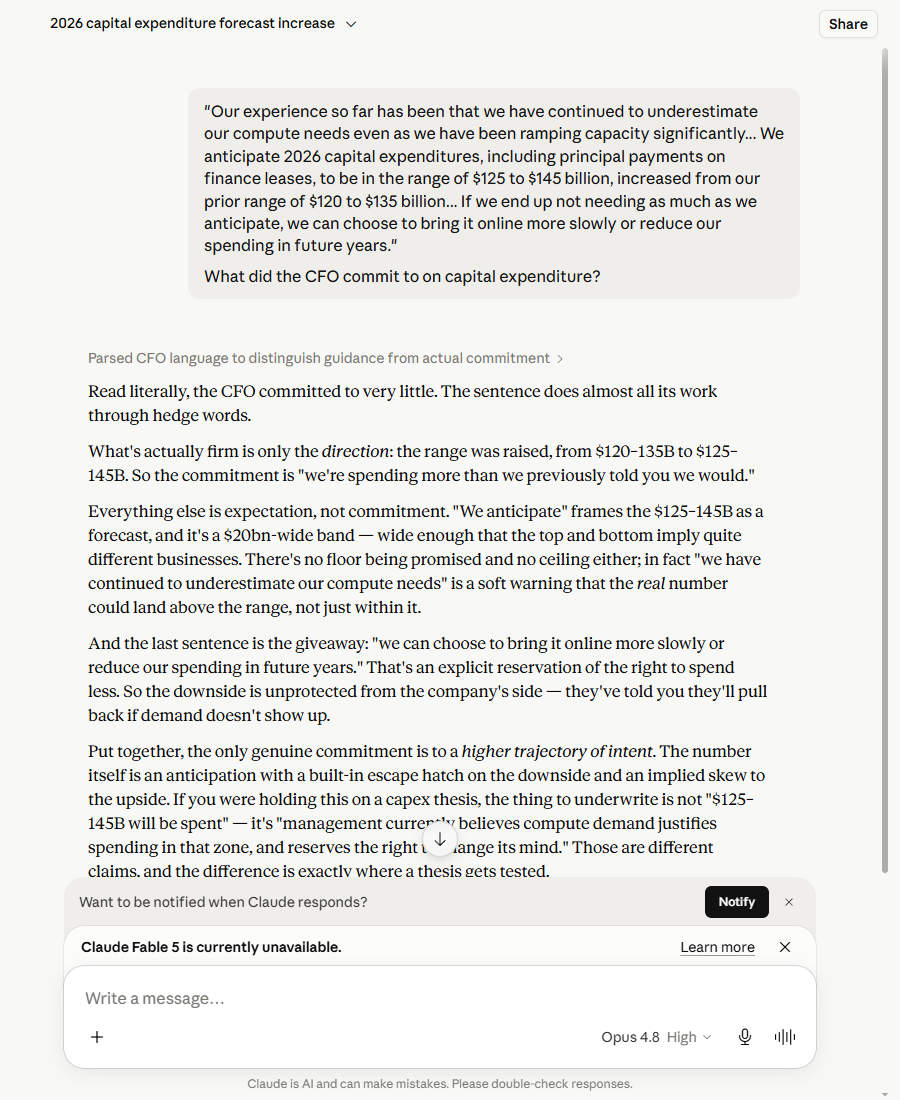
ChatGPT gave me the figures. Claude caught the word that moves the stock — and I never told it to look.
That’s the divergence. ChatGPT read the numbers and the obvious downside hedge. Claude read the room — it caught the signal pointing the other way, the one that explains why a revenue beat still cost shareholders roughly 8%. Claude wins this one outright, and it’s the dimension that matters most.
Dimension 3 — Does structure close the gap?
Here’s where the honest version of this post diverges from the hit piece it could have been. I ran the same passage a third time, this time with the Prompt Stack structure — a role, a filter, a risk question, a one-line verdict instruction.
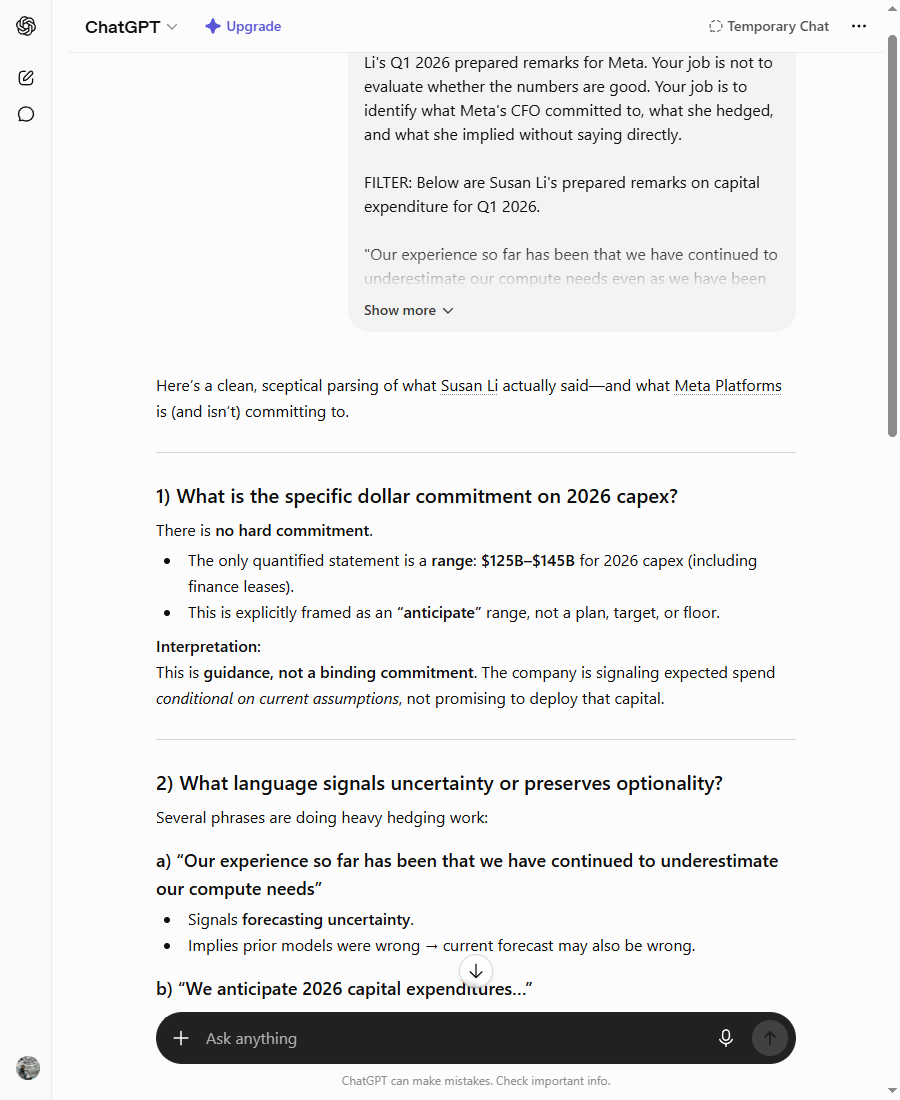
With that scaffolding, ChatGPT caught it. It named “continued to underestimate” as a hedge doing “heavy hedging work,” spelled out five separate phrases that leave Meta room to spend less, and worked out for itself that the underestimate framing is load-bearing for a bull case on the stock — “absolutely central to justifying the scale of spending.” That’s the analysis it skipped on the bare question. The structure brought it out.
So the finding isn’t “ChatGPT is bad at this.” It’s narrower and more useful: ChatGPT can read the hedge, it just needs you to ask the right way. Claude reads it on the first plain question.
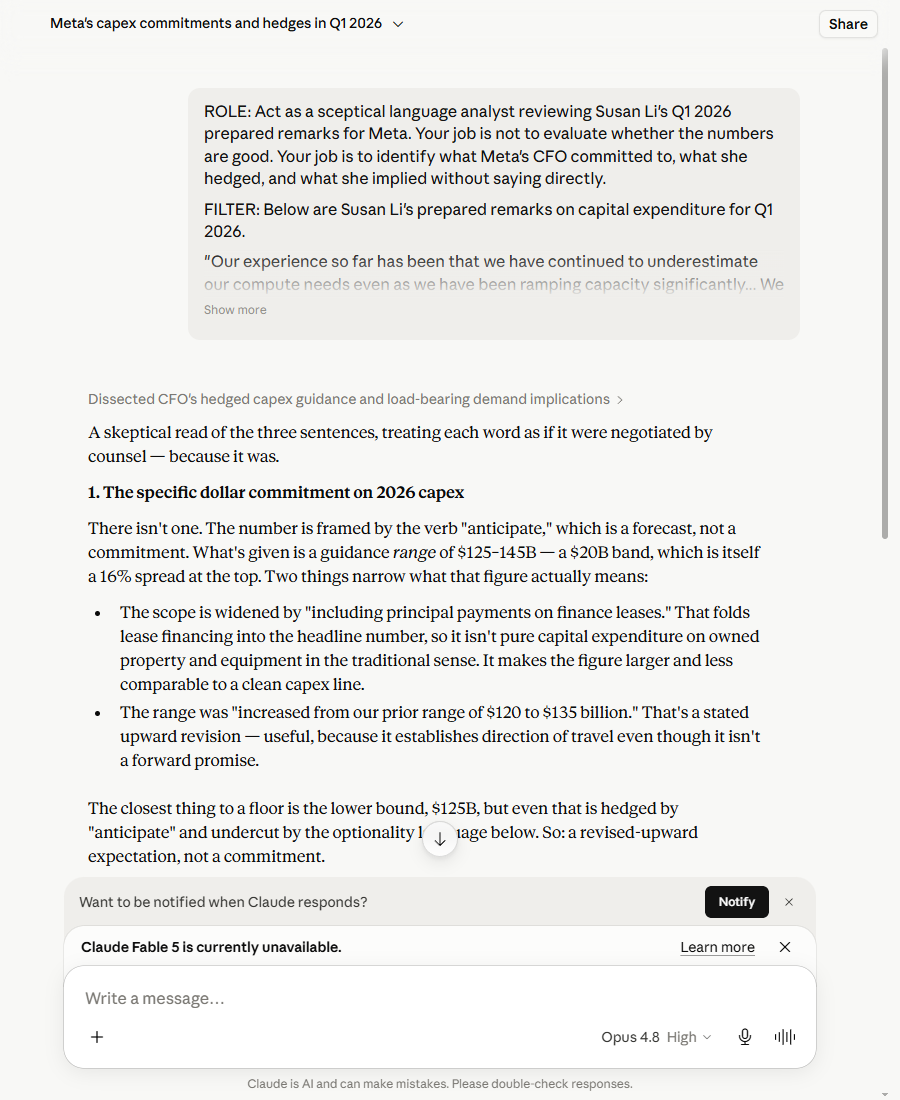
Claude with the structure went further still. It made one observation neither tool made unprompted: the spend-less escape clause is explicitly parked in future years, not 2026 — “the escape hatch is placed where it costs least to advertise.” The freedom to spend less, in other words, does very little to soften this year’s number; it just sounds reassuring. That’s the kind of second read you’d pay an analyst for. At its best Claude goes further; once you give ChatGPT the structure, it wins back most of the gap.
Dimension 4 — What management didn’t address
The last test: paste the fuller prepared remarks and ask, with no pre-list to check against, what a careful investor would expect management to cover that simply isn’t here. This is the absent-topic audit — the conspicuous silences.
The same caveat as Dimension 1, louder: ChatGPT was back on the weaker fallback model for this one, so it’s not a same-tier read. With that flagged, ChatGPT did fine — a competent numbered list of generic gaps: no capital-return policy, thin segment detail, no Reality Labs operating loss, vague regulatory specifics. The list any earnings checklist would produce. Accurate, but it reads like a checklist applied to the call rather than an audit of this call.
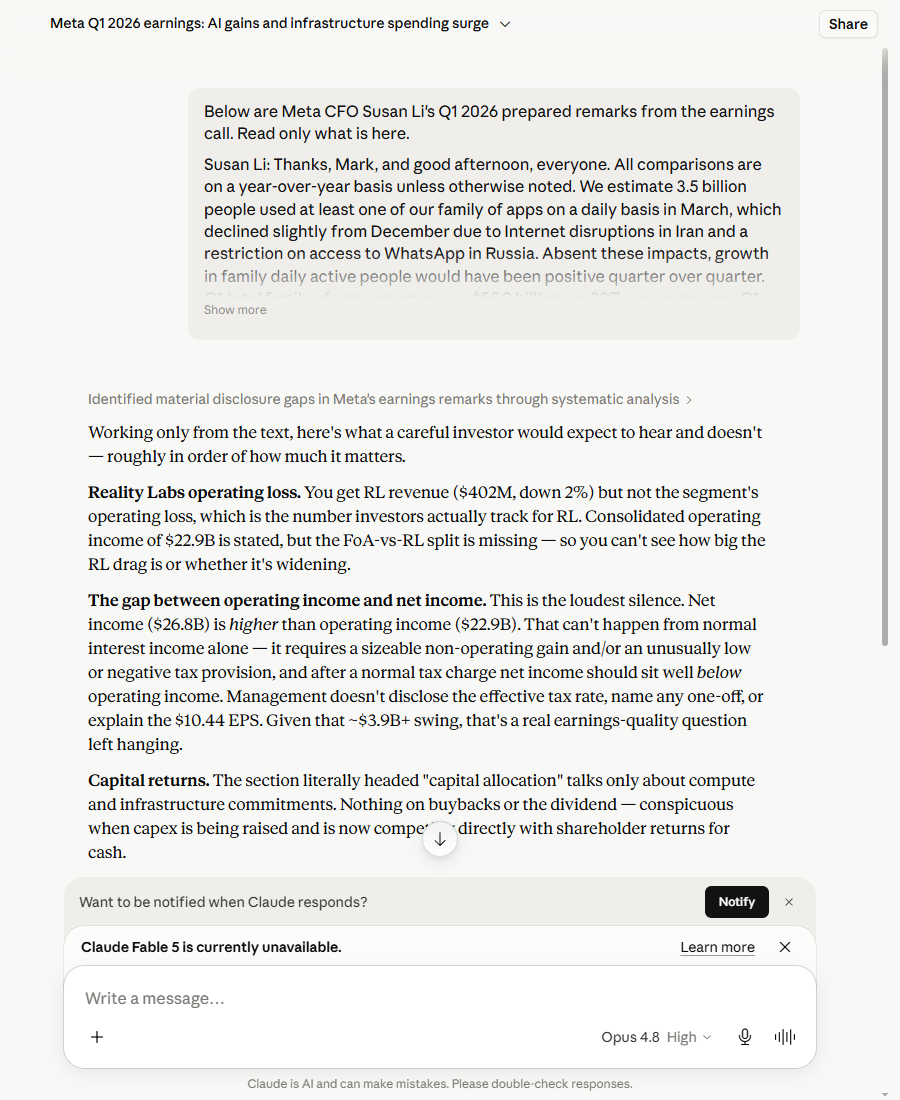
Claude’s read did the real work. I asked the same bare question and got back eight material absences, ranked by how much they matter. The one that stopped me: it spotted that the section literally headed “capital allocation” discussed only spending and said nothing about buybacks or the dividend — conspicuous when the capex bill is going up and now competes with shareholders for the same cash. I hadn’t clocked that gap myself until it pointed at it. It flagged the missing return on the AI spend in one clean line: “You’re given the cost side of the AI story without the return side.” That’s the audit of this call, not a generic one.
On a fair-tier rerun the gap might narrow. On what I ran, Claude’s absent-topic read was the more useful of the two by a clear margin.
The summary table
| Dimension | ChatGPT | Claude |
|---|---|---|
| Document discipline | Equal* | Equal |
| Hedge detection (unprompted) | Worse | Better |
| Structured prompt (Prompt Stack) | Better than its own bare read | Better |
| Absent-topic detection | Worse* | Better |
| Overall | Better once structured; needs the prompt | Better unprompted, for reading the language |
* ChatGPT was on a weaker fallback model for these two dimensions after hitting its free-plan cap — not a same-tier comparison. Treat both with caution.
ChatGPT vs Claude for earnings calls: the verdict
For reading prepared remarks — what was committed, what was hedged, what was carefully left out — Claude is the one I’d open first. It caught the upward signal in “underestimate” on the bare question, the question most people would type, and it read the conspicuous silences as an audit of this specific call rather than a generic checklist. That’s the whole job on results morning, and it did it without being coached.
But this isn’t a one-sided result, and pretending it is would be dishonest. The moment you give ChatGPT the Prompt Stack structure, it gets to nearly the same place — it named the hedge, spelled out the room to spend less, worked out what the bull case depends on.
The real finding is that structure matters as much as tool choice: a structured prompt to either tool beats a bare prompt to the better one.
If you want the analysis on the first plain question, that’s Claude.
The one condition that would flip this: a fresh model. These tools update faster than posts can keep up. This verdict is dated 18 June 2026, on Opus 4.8 and GPT-4o, and I’d re-run it the morning of any results I cared about rather than trust a comparison from months back.
Field Report
What worked: Claude caught the upward “underestimate” hedge unprompted and read the absent topics as an audit of this call, not a generic checklist. ChatGPT, given the Prompt Stack structure, closed most of the gap — it can read the hedge, it just needs to be asked properly.
What didn’t: ChatGPT’s bare-question read missed the upward signal entirely. And its free plan hit a message cap mid-test, dropping two dimensions onto a weaker fallback model — so those two aren’t a fair same-tier comparison. A paid tier would remove that asterisk.
Bottom line: Useful, with a clear split. For reading management language on the first plain question, Claude. For ChatGPT, the Prompt Stack structure does the heavy lifting. Re-run on the current models before you lean on either — these change faster than the verdict can.
The catch from this test — Claude flagging “underestimate” without being asked — is logged with the others on the catches page, where I keep a running record of the times an AI caught something I’d have wanted a human analyst to catch. For the full structured workflow on any earnings call, rather than the one passage I tested here, the five-prompt walkthrough is the place to start. This was the two-tool cut; for how all four tools handle real trades — and the specific way each one fails — see the four-tool audit. On results morning, for reading the prepared remarks, Claude is what I open first.

Ben tests ways of getting reliable answers from AI on his own investing — documenting what each model got wrong, what each one caught, and the prompts that survived the cuts. About Ben →
The site runs AI on real investing decisions. Start with the Prompt Stack for the four-stage framework, or the Field Guide PDF for the condensed version — free, no email.