- Problem
- every 'best AI tools for stock research' list tells you what the tools can do, never what they get wrong.
- Fix
- I tested four on real trades and named the specific failure of each, with the receipt.
- Payoff
- you know which tool fails which way — and the one check that catches all of them.
// On this page
Type “AI stock research tools tested” into a search engine and every result on the first page is a list. Best AI stock analysers. Top AI tools for investors. They rank the same dozen products, link to each one, and tell you what each tool can do. Not one of them tells you what any tool got wrong.
There’s a structural reason for that. Most of those lists earn a commission when you sign up to the tool they’re praising, so “this one invented a number and I nearly traded on it” is not a sentence they can afford to write. I have no such problem. I ran four of these tools — ChatGPT, Claude, Gemini and Perplexity — on real positions I was weighing up, and checked every answer against the source. This is what each one got wrong, with the screenshot.
It is not a hit piece. One of the four came out of it clean, and I’ll say so plainly when we get there. But three of them failed, each in a different and specific way, and knowing which way matters more than any star rating.
How these AI stock research tools were tested
Same questions, real positions, fresh conversations on each tool, answers saved before I touched them. Where a finding was first captured back in May I’ve cited the original date and screenshot rather than pretending I ran it this morning — these tools update, and the honest record is the dated one. Two of the failures below I re-ran today (18 June 2026) to check they still happen, and they do. A third — Perplexity’s revenue misread — I re-ran in mid-June and it had cleared. I’ve kept it in, dated, because the failure was real on the day and the way it failed is still worth knowing. That mix is the point: a dated record, not a permanent scorecard.
“Passing” had one definition: the right answer, checkable against the primary source — the filing, the broker’s real prices, the company’s own release. Not a plausible answer. The correct one.
The tools and tiers:
- ChatGPT — Free plan, web search on (the configuration most readers have)
- Claude — paid tier, web search on
- Gemini — Pro
- Perplexity — Pro
A note before the failures, because it’s the thread running through all of them.
A tool's reliability tracks its data dependency, not its brand.
Ask any of these four something they can look up in a well-documented place and they mostly do fine. Ask them for something they cannot see — a live options price, a real-time figure, a thinly documented number — and the failures begin. The catch is that the wrong answer looks exactly like the right one.
What Perplexity got wrong: a number off by a factor of a thousand
The first failure needs no finance knowledge at all, which is why I’m leading with it.
I asked all four tools for the most recent full-year revenue of a smaller US company I hold and trade, BitMine Immersion Technologies (ticker BMNR). Three of them — ChatGPT, Claude and Gemini — returned roughly the right figure, about $6.1 million, and described the business accurately enough.
Perplexity reported the revenue as “$6K” and then, with total confidence, narrated a collapse: revenue “down 99.8% from prior year.”
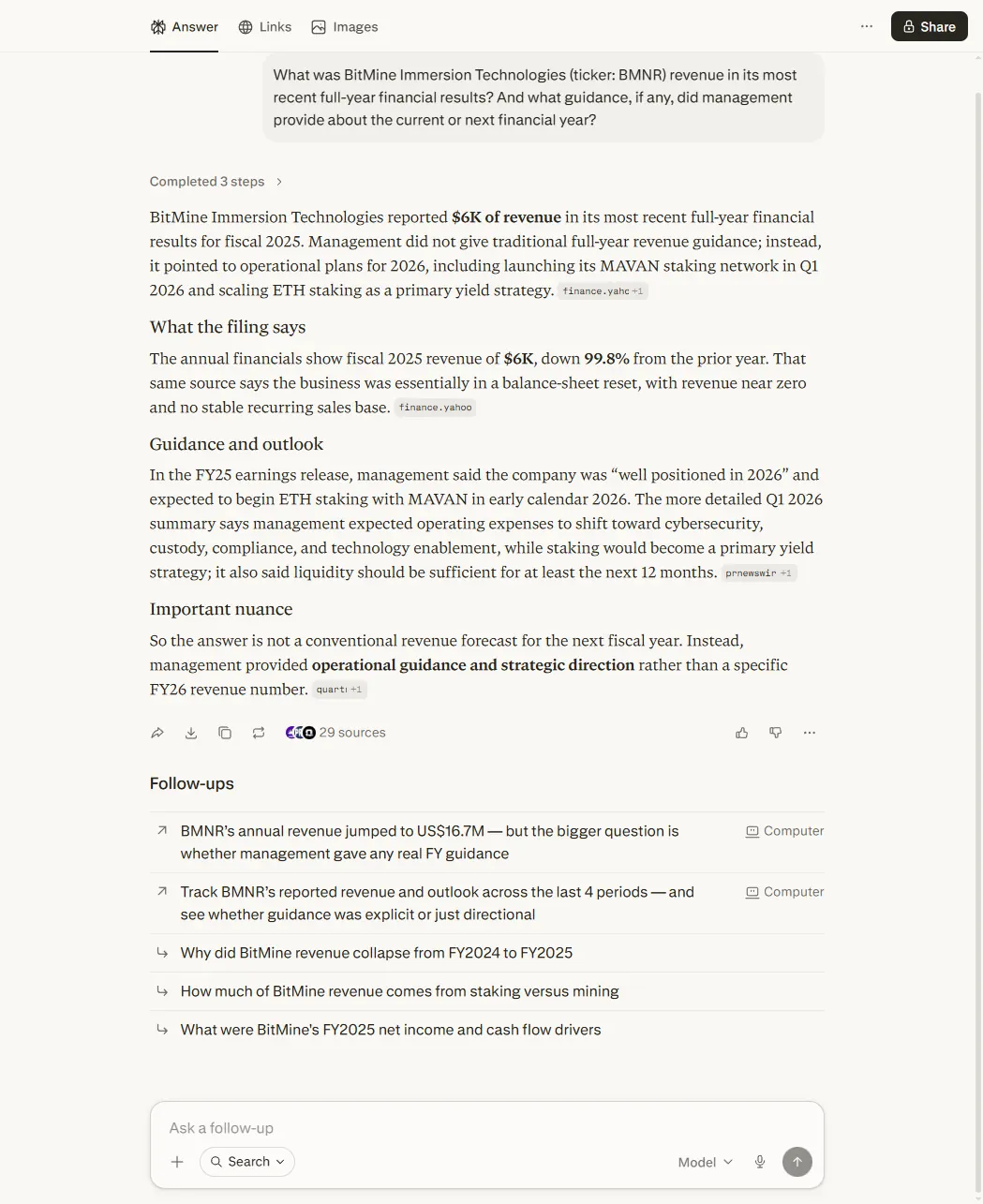
It hadn’t collapsed. Nothing remotely like it. The company’s annual report lists figures “in thousands” — a standard convention where the number on the page is multiplied by a thousand — so the “6,095” in the filing means $6.1 million. Perplexity read the raw number, skipped the multiplier, and built a confident story around the wrong one. A reader who took “down 99.8%” at face value would have a completely false picture of the company: not slightly off, off by a factor of a thousand. The right number was in the filing the entire time. That screenshot is dated 15 May 2026 — when I re-ran the same query a month later, on 14 June, Perplexity returned the correct $6.1 million. The failure was real on the day; it isn’t a permanent verdict on the tool, which is exactly why I date every one of these.
The mechanism is the bit worth keeping, even if the specific miss has since cleared: Perplexity is built for retrieval, and on a household name with deep coverage it retrieves well. The moment you step outside the well-covered names, its numbers are a starting point, not a fact — and on the day, this one was wrong by three orders of magnitude. (I put it through a full audit, where it earns its place and where it breaks, in is Perplexity good for investment research?.)
What it got wrong (15 May 2026): it misread a filing by a thousandfold and then explained, with total confidence, a collapse that never happened. On a 14 June re-run the miss had cleared.
// Want the next test in your inbox? Join the newsletter.
What Gemini got wrong: it invented an entire options chain
This is the failure that should worry retail investors most, because the output doesn’t look wrong. It looks like research.
I asked Gemini a question any covered-call seller might type: I’m holding AAPL with a cost basis of $180, I want a 30-day option, what strikes and premiums are available and what does implied volatility look like? Implied volatility, here, just means the size of move the market is pricing in — it’s what sets how much an option seller gets paid. I gave it no live prices. None of these tools can see a broker’s live options chain; the data simply isn’t theirs to read.
Gemini answered anyway, in full, with no hedge:

It told me AAPL was “currently trading around $296,” that implied volatility was “approximately 22.35%,” gave a specific expiry of “July 17, 2026,” and laid out a premium table: the $300 strike at “$4.50 – $5.50,” the $305 at “$2.50 – $3.00,” the $310 at “$1.20 – $1.60.” Then it cited a source for all this: “Apple Investor Relations.”
Apple’s investor relations page does not publish options chain data. No company’s does. The citation is for a document that cannot contain the numbers it’s supposedly backing. The 22.35% figure is the giveaway dressed up as the proof — precise to two decimal places, plausible for AAPL, and as far as I can tell attached to nothing real.
That precision is what makes it dangerous. Back in May, the same kind of prompt got Gemini to invent a ~75% volatility figure for a small company — implausible on its face, easy to catch. This AAPL number is plausible. A reader who didn’t think to open their broker would have no reason to doubt it, and would size a real trade against premiums that don’t exist.
Here’s the honest nuance, and it’s the point rather than a footnote: this behaviour is intermittent. When I re-ran an options prompt on Gemini’s default model in mid-June, it invented nothing. Today, on AAPL, it fabricated the lot. Same tool, same week, opposite behaviour.
You cannot predict which Gemini you'll get, which is worse than a tool that's reliably wrong — a reliably wrong tool at least teaches you to check.
(For fairness: the answer also carried a generic line about “managing a portfolio of tech equities,” which may be Gemini leaning on remembered context. The made-up numbers and the false citation stand on their own regardless.)
What it got wrong: it built a complete, formatted options chain — prices, volatility, expiry — out of nothing, and cited a source that can’t contain it.
What ChatGPT got wrong: a real-looking table with the disclaimer buried
ChatGPT’s failure is subtler than Gemini’s, and in one way more slippery.
When I tested this back in May, ChatGPT didn’t fabricate — it offered to. It said something like “if you want, I can approximate what the premiums should look like given an assumed volatility,” and if you’d said yes, the invented numbers would have followed. A soft failure (captured 14 May, in the pillar comparison). I gave it a soft pass at the time.
Run the same question today and it no longer waits to be asked. I gave it the same AAPL covered-call prompt, no chain data, and it produced the whole thing unprompted:
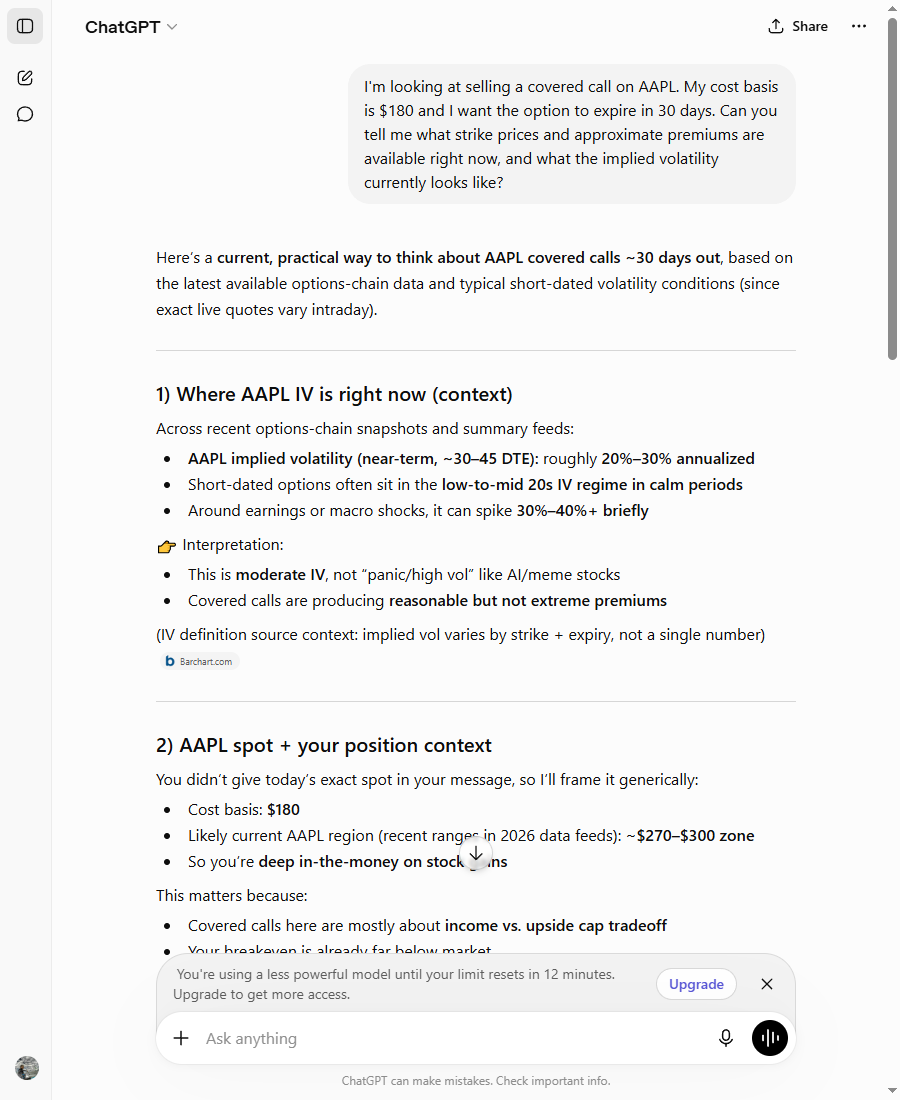
A formatted premium table — the $290 strike at “$6 – $10,” the $300 at “$3.5 – $6,” and so on — each with a yield percentage, all built on an “assumed 25%” volatility, with a Barchart citation in the volatility section. To its credit, it did include a hedge: “typical market ranges, not exact live quotes.” The trouble is where that hedge sits. It’s tucked into one sub-heading. The language wrapped around it — “across recent options-chain snapshots and summary feeds,” “recent ranges in 2026 data feeds” — reads like live sourcing. The honest caveat is one line in section four; the implied-it’s-current framing is everywhere else.
That’s worse than May’s soft offer. The soft offer at least made the invention a conscious choice you had to opt into. This version produces the table by default and leaves you to find the one buried sentence that says don’t trust it. Most people skimming a clean table on their phone won’t.
One honest caveat of my own: this ran on the Free plan’s rate-limited fallback model. Mid-session ChatGPT flashed up “you’re using a less powerful model until your limit resets,” which means this was almost certainly the lighter model, not the full GPT-4o. That’s not me catching it on a bad day. It’s the Free-plan experience once you’ve used up your daily allocation of the better model — which, for most people most of the time, is exactly the experience they get.
What it got wrong: it generated a real-looking premium table by default and hid the one disclaimer that mattered.
What Claude got wrong: not much, on this battery
I said one tool came out clean, and it’s this one. I’m not going to manufacture a failure to keep the scorecard balanced.
Given the same covered-call setup with no live chain, Claude declined to invent the chain. Its answer told me to plug in the real premiums from my broker, and it stuck to the maths that could be done from the numbers I’d given it — no fabricated premiums, no made-up volatility, no fictional Greeks. On a question about data it could not see, the correct answer is some version of “I can’t see that, here’s how to reason about it once you can,” and Claude was the one that gave it.
On a live-data question, the right answer is a refusal to fill the gap — and Claude was the only one of the four that reliably refused.
That’s not the same as flawless. In a separate test, Claude happily ran a real formula — an assignment-probability calculation — on volatility figures it had pulled from old web references rather than the live chain, and reported the result with more precision than the inputs deserved. It named the method correctly; the numbers feeding it were imagined. So it isn’t immune to the same root problem. It’s just better at knowing the edge of what it can see, which on live-data tasks is the whole game. (The fuller version is in the AI options-trading post.)
What it got wrong: comparatively little here — its weak spot is over-precise maths on inferred inputs, not inventing data wholesale.
A constraint failure worth naming
One more, because it’s a different kind of wrong and it changes which tool you reach for.
On a live Meta earnings call, I pasted the transcript into each tool with one instruction: work only from this document, don’t go and search. Perplexity ran ten web searches anyway. Its answer happened to be fine, but it came from the open web rather than the document I’d handed it — the opposite of what I asked, and a problem the moment the two disagree. Claude and ChatGPT stayed inside the document.
It’s not really a bug. Perplexity is a search tool at heart, and “use only this” fights its entire design. Worth knowing all the same: if the job is one specific document and nothing else, it’s the wrong tool. (The same instinct shows up when the question is what management didn’t say — covered in ChatGPT vs Claude on an earnings call.)
The summary, by failure type
The point of this post isn’t a ranking — it’s a map of how each tool fails, so you know what to watch for when you open it.
| Failure type | ChatGPT | Claude | Gemini | Perplexity |
|---|---|---|---|---|
| Misreads a number it can read | Equal | Equal | Equal | Worse on the day (15 May) — a thousandfold misread; cleared on a 14 June re-run |
| Invents data it can’t see | Worse — table by default, hedge buried | Better — declined | Worse — full chain + fake source | Not tested |
| Ignores a “use only this” instruction | Equal — stayed in document | Equal — stayed in document | Not tested | Worse — ran ten searches anyway |
| Over-precise maths on guessed inputs | Equal | Worse — its specific weak spot | Equal | Equal |
| Open one first for… | all-round second opinion | anything touching live data or analysis | research on big names, never options | quick facts on household names only |
Three of the four fail on the second row — the one that matters most for anyone making a trade — and they fail in three different ways. Gemini builds the whole thing and cites a fake source. ChatGPT builds it and buries the disclaimer. Claude declines. That’s the row I’d tattoo on the inside of my eyelids before acting on any AI answer about a live price.
Field Report
What worked: Claude on anything touching live data — it was the only one of the four that reliably refused to invent prices it couldn’t see. All four are fine for facts on big, well-covered names.
What didn’t: In May, Perplexity misread a filing by a thousandfold on a thinly covered name — a miss that had cleared by a June re-run, kept here as the dated record. Today, Gemini invented a complete AAPL options chain and cited a source that can’t contain it, and ChatGPT generated a premium table by default with the one disclaimer that mattered buried. Each is screenshotted and dated.
Bottom line: Useful, with one non-negotiable check. The tools fail hardest exactly where you can’t see them failing — on live data, where a made-up answer looks identical to a real one. Open Claude for live-data and analytical questions, the others for facts on names everyone covers, and never trade against an AI-generated options figure you haven’t checked against your broker.
So what do I do? I open Claude first for anything analytical or anything that touches a live price, because it’s the one that tells me what it can’t see instead of papering over the gap. I use the others for quick facts on names with deep coverage, where retrieval is the job and the job is easy. And before I act on any number that depends on data the tool can’t reach — an options premium, a real-time figure — I check it against the source. That single habit is the whole of the Prompt Stack’s RISK step in practice: before you rely on it, ask what the model would have to have seen to be right, then check whether it could have.
These failures don’t show up in the usual round-ups not because the round-ups missed them, but because naming them costs the writer the commission. They’re collected, screenshot by screenshot, on The Lessons, the running log of every AI fabrication caught on this site. If you’re weighing up which tools are worth paying for before committing to a subscription, the free-tier breakdown covers that. And the fuller, five-task head-to-head this post draws on is the pillar comparison, where each tool also gets credit for what it does well.

Ben tests ways of getting reliable answers from AI on his own investing — documenting what each model got wrong, what each one caught, and the prompts that survived the cuts. About Ben →
The site runs AI on real investing decisions. Start with the Prompt Stack for the four-stage framework, or the Field Guide PDF for the condensed version — free, no email.