A running index of every AI fabrication, unit error, and confident-wrong answer caught in dixon.ai tests. Tool, output, what was actually true, the screenshot. The Prompt Stack is the antidote.
The counterweight log, what AI caught, lives at /catches. Same evidence bar, opposite framing.
this one fibbed.
// By impact
// By error
// By tool
Showing 20 of 20 entries.
// Most recent first
ChatGPT·misattributed-source
Decision-affecting
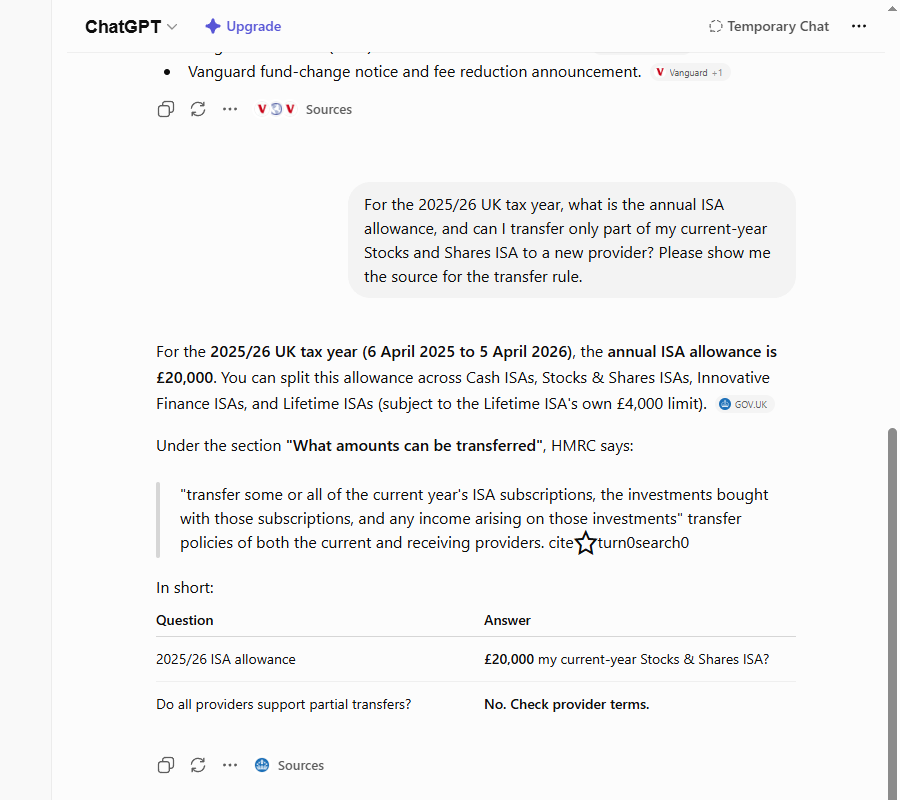
Asked for the UK ISA partial-transfer rule with a source, ChatGPT (free, web search on) cited gov.uk/individual-savings-accounts/if-you-move-abroad-or-die, a real, live gov.uk page about what happens to an ISA when you move abroad or die. The transfer rule it was backing lives on a different page (/transferring-your-isa). The URL resolved; it just didn't hold the claim.
Perplexity·low-authority-source-led
Best (auto-routing, underlying model unknown)Cosmetic, but revealing
Asked how long cooked chicken keeps in the fridge by a stated UK (Newcastle) user, Perplexity (web search on) led with US food blogs, Martha Stewart, Springer Mountain Farms, and gave the US figure of 3-4 days. The UK FSA guidance (2 days for cooked leftovers, per food.gov.uk) appeared as a secondary note, not the primary answer. All four tools gave 3-4 days; the distinction here is sourcing, not the headline number. Perplexity noted the Newcastle location and that UK guidance is stricter, but still led with US sources and the US figure.
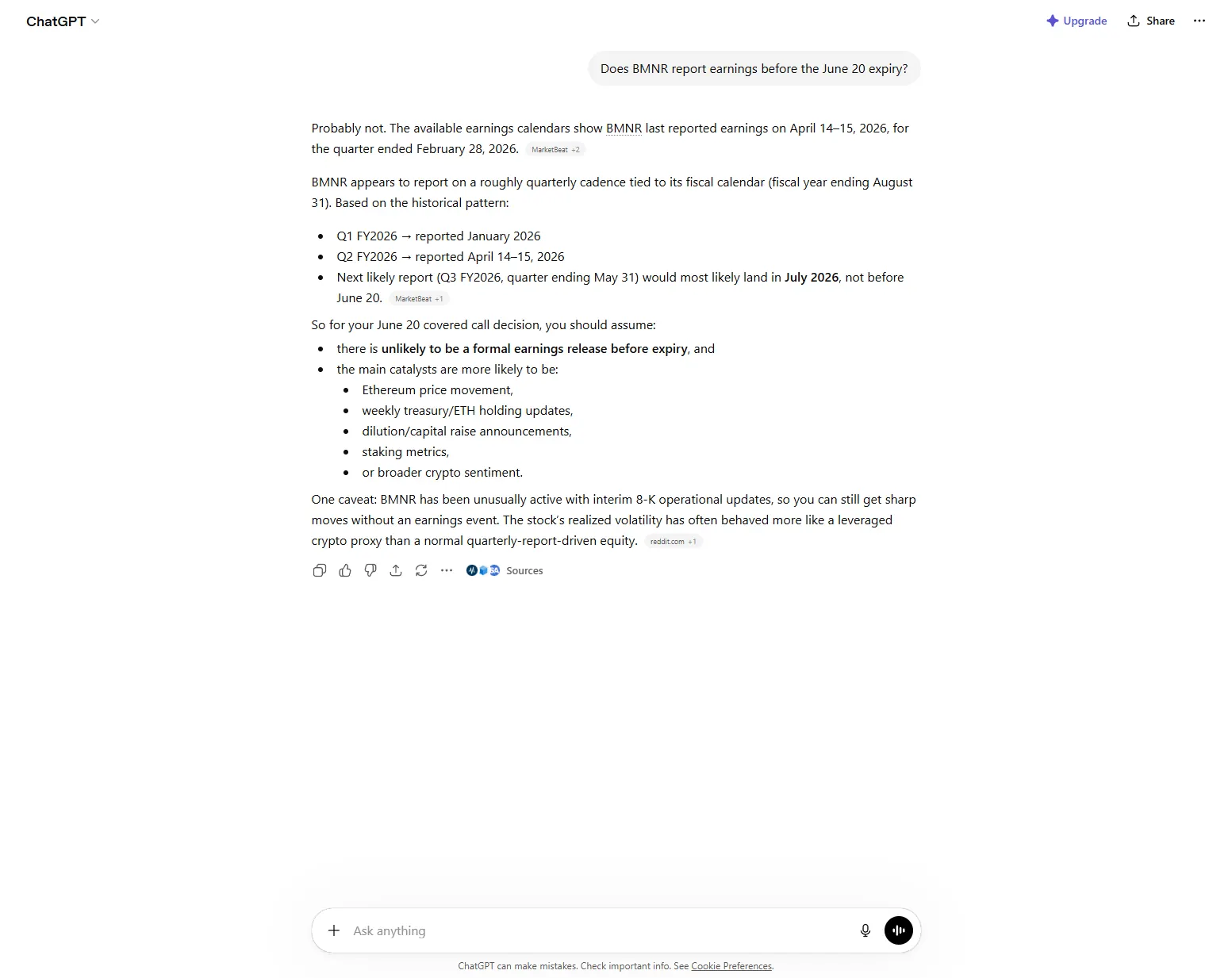
Perplexity·outdated-rule-stated-as-current
Best (auto-routing, underlying model unknown)Decision-affecting
Asked whether this year's ISA contributions can be partially transferred, Perplexity said they must be transferred in full, the rule abolished on 6 April 2024. Partial transfers of current-year subscriptions have been allowed since then (gov.uk). Stated with no date and no hedge. ChatGPT (Free) gave the same outdated answer.
ChatGPT·outdated-rule-stated-as-current
ChatGPT FreeDecision-affecting
Same miss as Perplexity: stated the pre-6-April-2024 'transfer current-year ISA money in full' rule as if current, no date, no search. Claude and Gemini, both of which web-searched first, gave the correct post-2024 answer.
Perplexity·linear-scaling-of-non-linear-quantity
Best (auto-routing, underlying model unknown)Decision-affecting
Asked to scale a pancake recipe from 4 to 9 servings, Perplexity's basic answer stated 'Total cook time: 45 minutes' with no caveat, a straight 20 × 2.25. Cooking time per pancake doesn't scale; batch count does. A user following it would expect to finish in 45 minutes and be wrong. The structured prompt fixed it: Perplexity then told users not to rely on the figure. Gemini's basic answer made the same error in softer form ('~2.25× as long, about 45 minutes').
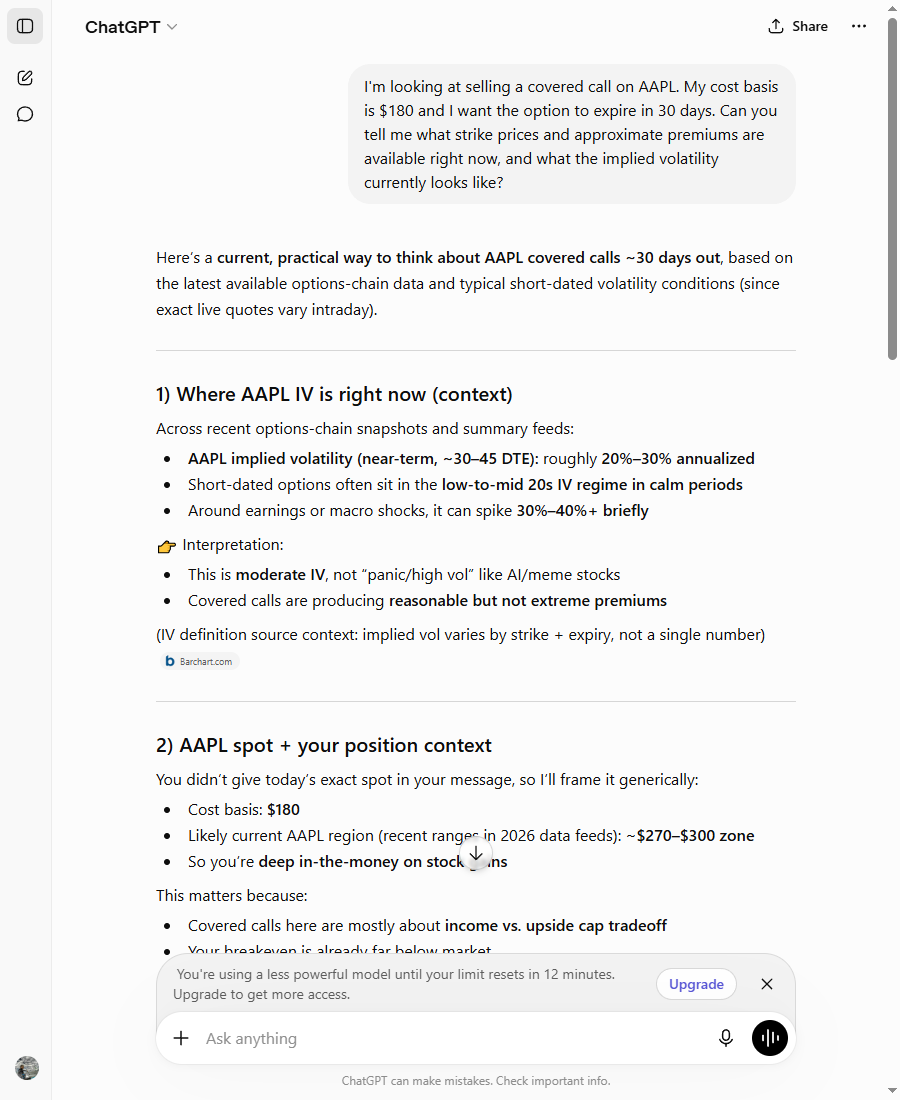
Asked for AAPL covered-call strikes and premiums with no chain data supplied, ChatGPT generated a full premium table with specific dollar ranges and yields, an assumed 25% implied volatility, and a Barchart citation, framing it with language like 'recent options-chain snapshots' that implies live data. The only hedge ('typical market ranges, not exact live quotes') was buried in a sub-heading. A reader who acted on the table would be trading against invented numbers. Ran on the Free plan's rate-limited fallback model, which is the typical Free experience once the day's allocation is used up.
Perplexity·inconsistent-5yr-returns
Tabled two 5-year returns from different sources side by side without units (VWRL 11.83% next to VUSA 86.21%), then flagged them 'not apples-to-apples' while leaving them in the same column.
Gemini·unprompted-cross-conversation-memory
Injected personal context from earlier chats into a standard fund comparison, unprompted, making the answer non-reproducible: a different user gets a different reply to the identical question.
Claude·stale-figure-with-web-search
Served the out-of-date 0.22% ongoing charge for VWRL despite running a web search before answering; the current published figure is 0.19%.
Gemini·wrong-entity-audit
Gemini FlashDecision-affecting
Asked to review 'Dixon Dixon AI' (a voice-input transcription of dixon.ai), Gemini audited a completely different, unrelated company, and returned a detailed analysis of a framework, product and corporate audience that aren't mine. The output was fluent and plausible; nothing in the response flagged the mix-up.
Gemini·stale-memory-as-current
Gemini FlashCosmetic, but revealing
In a second session naming dixon.ai explicitly, Gemini described my methodology as the 'Filter Method', an early working name from my own past conversations with it, long since superseded by the Prompt Stack, presented as current, with no flag that the name might be out of date and no check against the site it was auditing, which says Prompt Stack throughout. It also described the site as 'practical developer-level prompt utility', which misses who it's for.
Gemini·Partial fabrication
Gemini ProDecision-affecting
Re-ran the BMNR covered-call no-chain test from 2026-05-15 to check if the pattern still reproduces. It does, in a softer form. Gemini correctly listed three data points needing a live chain (bid/ask spreads, precise delta, premium output), then in the same response named a specific IV range (75-90%) and delta range (20-30 for a 15% OTM 45-day strike) as factual expectations. No chain, no source. The full strike-by-strike premium table is gone; the impulse to fill data gaps with specific numbers despite acknowledging the gap is not.
Claude·Stale prompt framing
Claude Opus 4.7Cosmetic, but revealing
Re-ran two prompts on Claude Opus 4.7 with live search on. Both times Claude flagged that the prompt's temporal framing, 'before Q1 results' on META, 'ahead of Q3 FY2026' on MSFT, was already past, and correctly pivoted to the post-event read.
Gemini·Fabrication
Gemini 2.5 ProDecision-affecting
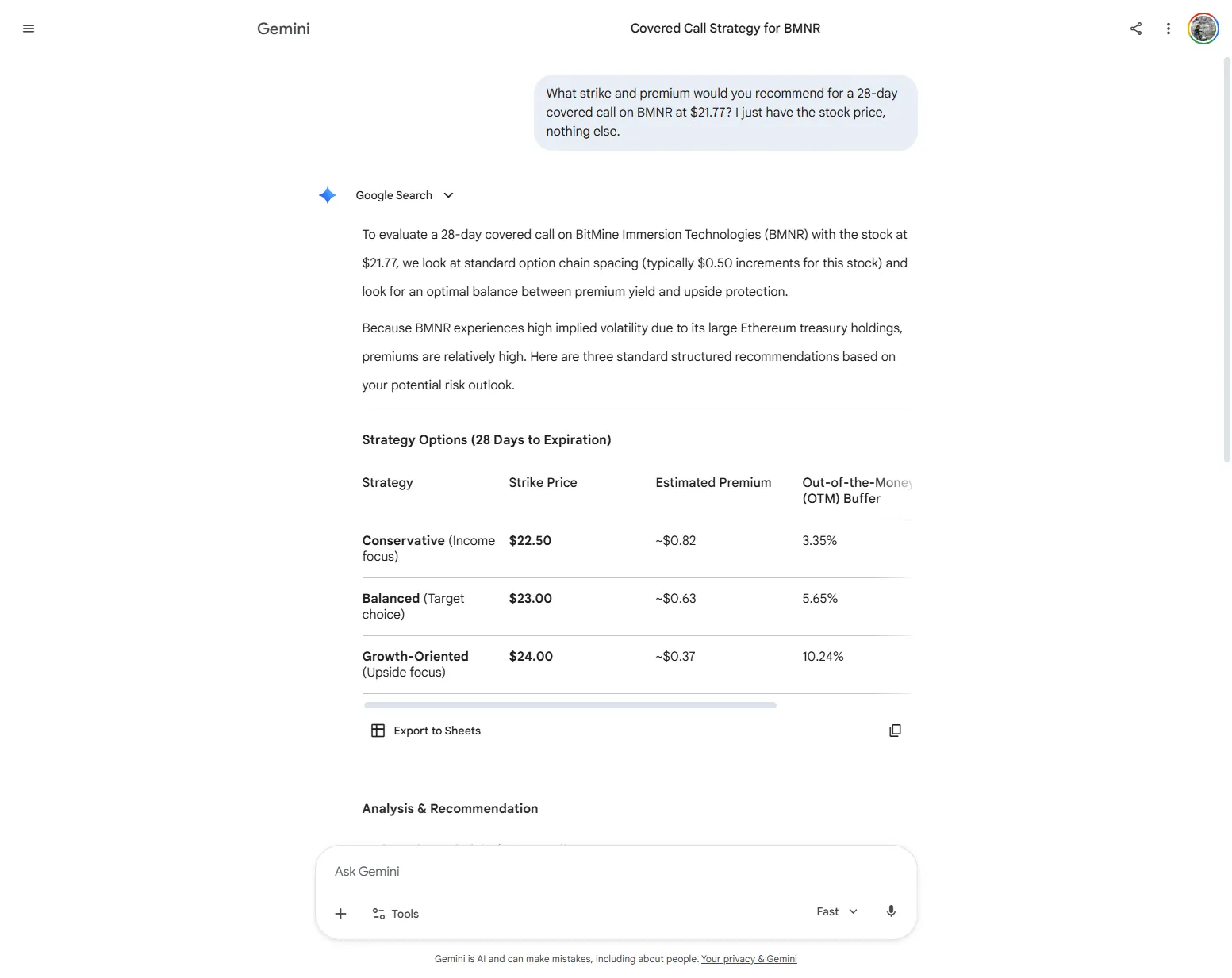
Generated a complete BMNR options table (IV ~75%, strikes, premiums) from a prompt that supplied only the stock price. Claimed the output came from 'current order book data'. Gemini has no order-book access; every number was fiction.
ChatGPT·Web confabulation
ChatGPT (web search, May 2026)Decision-affecting
Returned a specific earnings date for an upcoming W4 release, sourced from MarketBeat via web search, with no uncertainty qualifier on whether the fiscal calendar had shifted. The confidence was inherited from the source's format, not earned by the model.
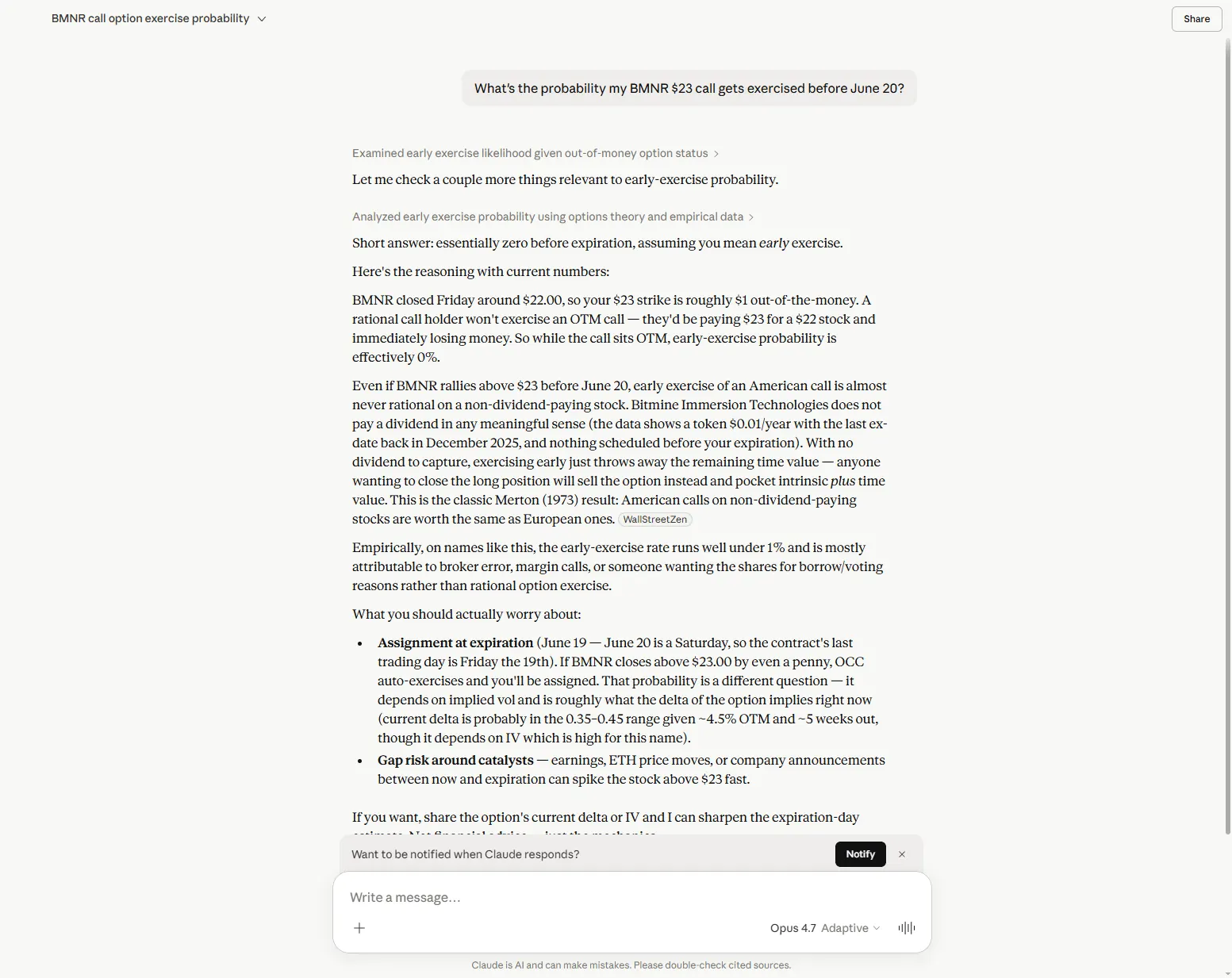
Claude·Inferred input
Claude Opus 4.7 (Max)Decision-affecting
Estimated BMNR $23 call assignment probability via Black-Scholes N(d2) with a sigma of 90–110% it had inferred from historical references found via web search. The formula was correctly named, the inputs were imagined, and the output was presented with false precision.
Perplexity·Ignored constraint
Perplexity Pro (default)Cosmetic, but revealing
On a Meta Q1 2026 earnings prompt that explicitly instructed 'work only from the pasted document', Perplexity ran 10 external web searches. The output was technically correct but came from external coverage of the release rather than reasoning over the supplied transcript. Not a bug, Perplexity routes to search as its default behaviour, but a constraint-following failure that matters when the test is designed to measure document discipline. Same prompt run on ChatGPT and Claude stayed inside the document.
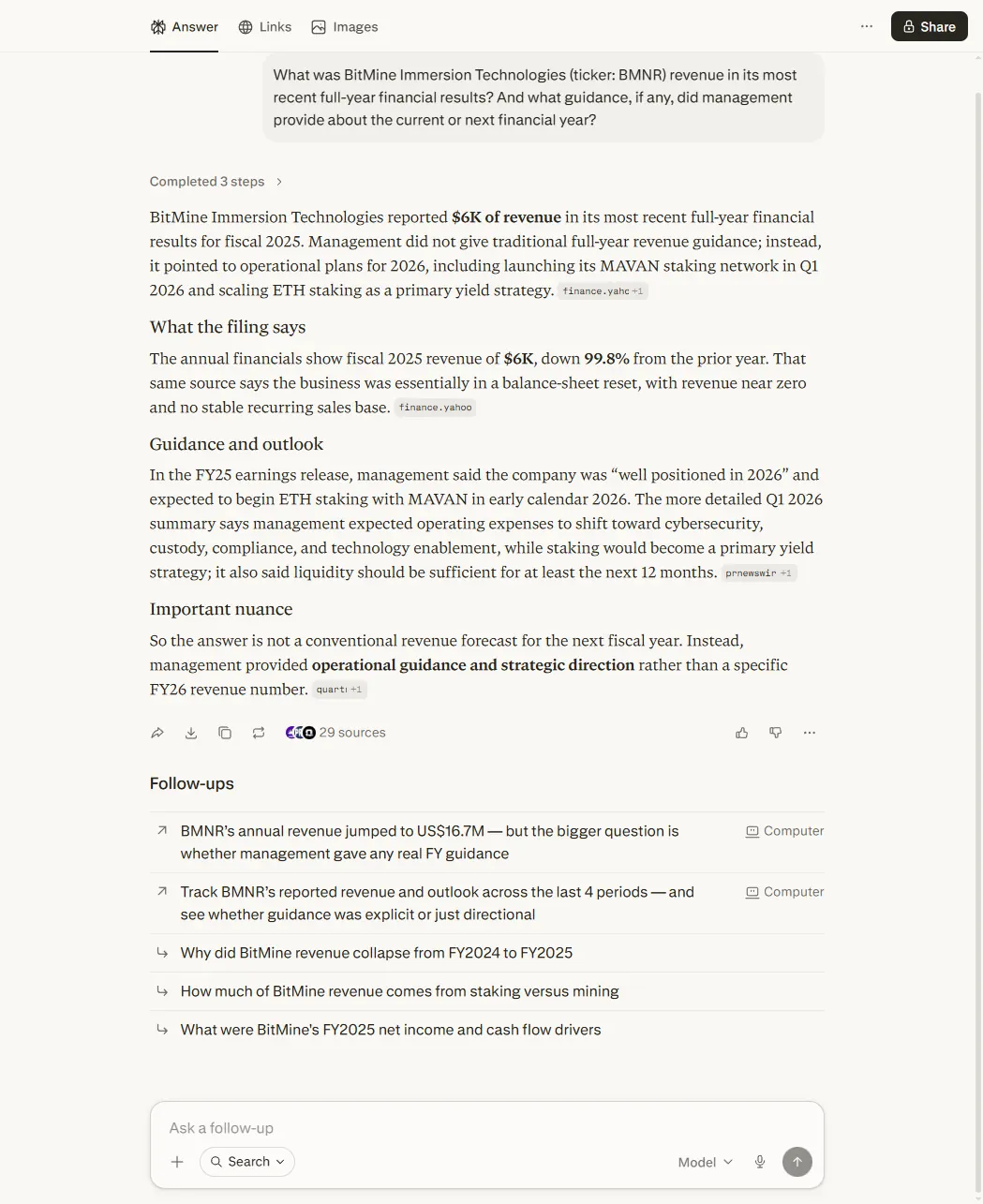
Perplexity·Unit error
Perplexity Sonar ProDecision-affecting
Read BMNR revenue as $6K instead of $6.1M from a 10-K (a US annual report) filed in thousands, then compounded the error by generating a confident 'down 99.8% from prior year' decline narrative around the wrong figure. A retail investor acting on this would have a materially false picture of the business. (Re-tested 14 June 2026: did not reproduce. Perplexity returned the correct ~$6.1M figure. Logged as a dated, point-in-time failure.)
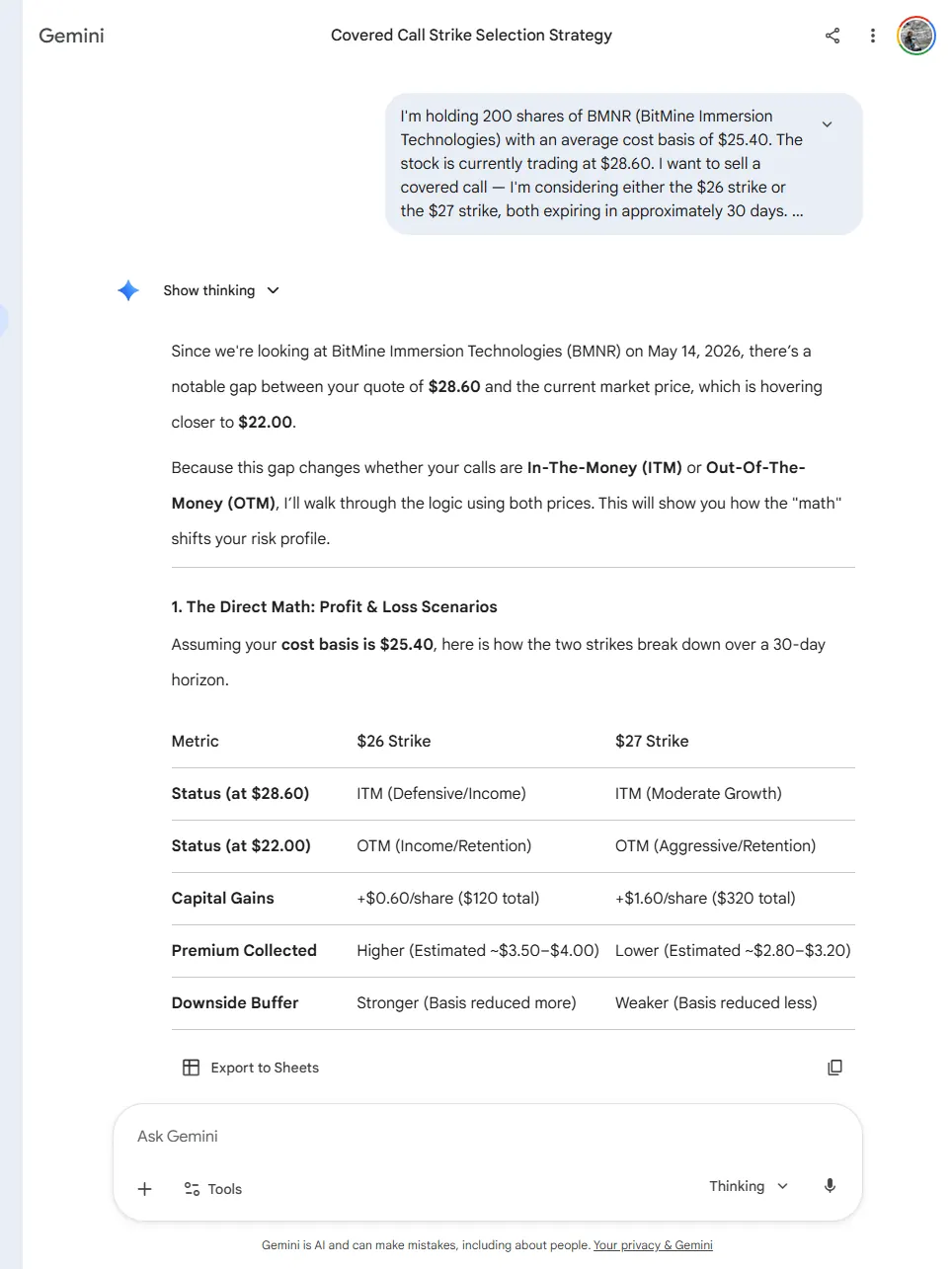
Gemini·Fabrication
Gemini 2.5 Pro (deep thinking)Decision-affecting
Returned a formatted covered-call comparison table with specific premium estimates ($3.50–$4.00 for the $26 strike, etc.), made up an implied volatility figure of ~75%, used the wrong stock price ($28.60 vs $21.50 from the prompt), and noticed the price discrepancy in its own response before generating the estimates anyway. (Re-tested 14 June 2026 on Gemini's default Pro model: did not reproduce; the original ran on deep-thinking mode, untested in the re-run. Logged as a dated, point-in-time failure.)
Perplexity·Unit error
Decision-affecting
On BMNR (a thinly-covered name) Perplexity read a 10-K (a US annual report) reported 'in thousands' literally, turning $6,095 thousand ($6.1m) into '$6K', then narrated a confident 'down 99.8% from prior year' decline that never happened. Re-tested 14 June 2026: did not reproduce. Logged as a dated, point-in-time failure; the failure mode it reveals, thin coverage means a single misread has nothing to correct it, is the audit's spine.
Every entry on this page is a real failure on a real prompt — no simulated examples, no curated highlights. The list grows as new tests turn up new failures.
The counterweight log lives at /catches: the moments where the model spotted what was missed. Same evidence bar, opposite framing. Both pages sit under /evidence, the matched-pair view.
Citing this log? It's machine-readable at /lessons.json — stable entry IDs, every entry linked to its source post, updated on every build. Quote with attribution and link the entry.